Release 8.0
A58227-01
Library |
Product |
Contents |
Index |
| Oracle8 Concepts Release 8.0 A58227-01 |
|
![]()
![]()
Like to a double cherry, seeming parted, But yet an union in partition; Two lovely berries molded on one stem.
Wm. Shakespeare: A Midsummer-Night's Dream
This chapter describes partitioned tables and indexes, and explains some administrative considerations for partitioning. It covers the following topics:
|
Attention: The features described in this chapter are available only if you have purchased Oracle8 Enterprise Edition with the Partitioning Option. See Getting to Know Oracle8 and the Oracle8 Enterprise Edition for information about the features and options available with Oracle8 Enterprise Edition. |
This section explains how partitioning can help you manage large tables and indexes in an Oracle database.
Partitioning addresses the key problem of supporting very large tables and indexes by allowing you to decompose them into smaller and more manageable pieces called partitions.
Once partitions are defined, SQL statements can access and manipulate the partitions rather than entire tables or indexes. Partitions are especially useful in data warehouse applications, which commonly store and analyze large amounts of historical data.
All partitions of a table or index have the same logical attributes, although their physical attributes can be different. For example, all partitions in a table share the same column and constraint definitions; and all partitions in an index share the same index columns. However, storage specifications and other physical attributes such as PCTFREE, PCTUSED, INITRANS, and MAXTRANS can vary for different partitions of the same table or index.
Each partition is stored in a separate segment. Optionally, you can store each partition in a separate tablespace, which has the following advantages:
The section "Basic Partitioning Model" on page 9-11 provides more information about partitioning concepts.
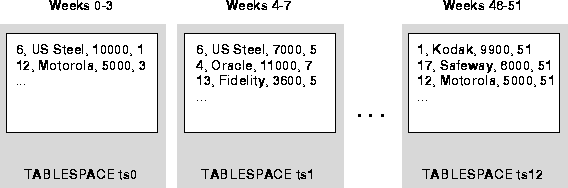
In Figure 9-1, the sales table contains historical data divided by week number into 13 four-week partitions. This SQL statement creates the partitioned table:
CREATE TABLE sales ( acct_no NUMBER(5), acct_name CHAR(30), amount_of_sale NUMBER(6), week_no INTEGER ) PARTITION BY RANGE ( week_no ) ... (PARTITION sales1 VALUES LESS THAN ( 4 ) TABLESPACE ts0, PARTITION sales2 VALUES LESS THAN ( 8 ) TABLESPACE ts1, ... PARTITION sales13 VALUES LESS THAN ( 52 ) TABLESPACE ts12 );
|
Additional Infromation:
For more examples of partitioned tables, see the Oracle8 Administrator's Guide. |
The Oracle server incorporates the intelligence to explicitly recognize partitions. This knowledge is exploited in optimizing SQL statements to mark the partitions that need to be accessed, eliminating ("pruning") unnecessary partitions from access by those SQL statements.
For each SQL statement, depending on the selection criteria specified, unneeded partitions can be eliminated. For example, if a query only involves Q1 sales data, there is no need to retrieve data for the remaining three quarters. Such intelligent pruning can dramatically reduce the data volume, resulting in substantial improvements in query performance.
If the optimizer determines that the selection criteria used for pruning are satisfied by all the rows in the accessed partition, it removes those criteria from the predicate list (WHERE clause) during evaluation in order to improve performance.
Partition pruning can eliminate index partitions even when the underlying table's partitions cannot be eliminated, if the index and table are partitioned on different columns. You can often improve the performance of operations on large tables by creating partitioned indexes which reduce the amount of data that your SQL statements need to access or modify.
The ability to prune unneeded partitions from SQL statements increases performance and availability for many purposes, including partition-level load, purge, backup, restore, reorganization, and index building.
This section identifies the classes of databases that could benefit from the use of partitioning, and characterize them in terms of the problems they present:
A Very Large Database (VLDB) contains hundreds of gigabytes or even a few terabytes of data. Partitioning provides support for VLDBs that contain mostly structured data, rather than unstructured data. These VLDBs typically owe their size to the presence of a few very large data objects (tables and indexes) rather than to the presence of a very large number of data objects.
There are two major categories of VLDB:
A VLDB may be characterized as an OLTP database if most of its workload is OLTP. Similarly a VLDB may be characterized as a DSS database if most of its workload consists of DSS queries.
Partitioning efficiently supports both OLTP VLDBs and DSS VLDBs.
Historical databases are the most common type of DSS VLDB. A historical database contains two classes of tables, historical tables and enterprise tables.
The time interval reflected in a historical table is a rolling window, so periodically the database administrator (DBA) deletes the set of rows describing the oldest transactions and allocates space for the set of rows describing new transactions. For example, at the close of business on April 30, 1997 the DBA deletes the rows (and all supporting index entries) that describe May 1995 transactions and allocates space for May 1997 transactions.
The vast majority of data in a historical VLDB is stored in few very large historical tables that present special problems due to their size and the requirement to smoothly roll out old data and roll in new data.
Partitioning addresses the problem of supporting large historical tables and their indexes by dividing historical data into time-related partitions that can be managed independently and added or deleted conveniently.
Mission-critical OLTP databases present special availability and performance problems even if they are not very large. For example, it may be necessary to perform scheduled maintenance operations or recover a 10-gigabyte table in a very short period of time, perhaps an hour or less. Also, the DBA may need a degree of control over data placement that is hard to achieve when a table or index is spread over multiple drives.
Partitioning can increase the availability of mission-critical databases if critical tables and indexes are divided into partitions to reduce the maintenance windows, recovery times, and impact of failures. You can also improve access performance to a critical table or index by controllin performance parameters on a partition basis.
Partitions enable data management operations like data loads, index creation, and data purges at the partition level, rather than on the entire table, resulting in significantly reduced times for these operations.
Partitioning can significantly reduce the impact of scheduled downtime for maintenance operations:
Partition maintenance operations are faster than full table or index maintenance operations. A speedup can be achieved equal to the ratio:
provided there are no interpartition stored constructs (global indexes and referential integrity constraints).
To further reduce downtime, a partition maintenance operation can take advantage of performance features that are available for table and index-level maintenance operations, such as the PARALLEL, NOLOGGING, and DIRECT (or APPEND) options where applicable.
Partition independence for the partition maintenance operations makes it possible to perform concurrent maintenance operations on different partitions of the same table or index, as well as concurrent SELECT and DML operations against partitions that are unaffected by maintenance operations.
For example, you can Direct Path Load into partitions PA and PB at the same time, while applications are executing standard SQL SELECT and DML operations against other partitions.
Partition independence is particularly important for operations that involve data movement. Such operations may take a long time (minutes, hours, or even days). Partitioning can reduce the window of unavailability on other partitions to a short time (few seconds) during operations that involve data movement, provided there are no inter-partition stored constructs (global indexes and referential integrity constraints).
Partition independence is not needed for short operations (no data movement) because these operations complete in a short time.
Some maintenance operations are unplanned events, required to recover from hardware or software failures that cause data loss or corruption. Recovery from hardware failures and many system software failures is accomplished by running the RECOVER command on a database, tablespace, or datafile. Any tables or indexes that have records in a tablespace or datafile being recovered remain unavailable during recovery. Increased availability is particularly important for mission-critical OLTP databases.
Because partitions are independent of each other, the unavailability of a piece (or a subset of pieces) does not affect access to the rest of the data.
Storing partitions in separate tablespaces provides the following benefits:
DSS queries on very large tables present special performance problems. An ad-hoc query that requires a table scan may take a long time, because it must inspect every row in the table; there is no way to identify and skip subsets of irrelevant rows. The problem is particularly important for historical tables, for which many queries concentrate access on rows that were generated recently.
Partitions help solve this DSS performance problem. An ad-hoc query which only requires rows that correspond to a single partition (or range of partitions) can be executed using a partition scan rather than a table scan.
For example, a query that requests data generated in the month of October 1997 can scan just the rows stored in the October 1997 partition, rather than rows generated over many years of activity. This improves response time and it may also substantially reduce the temporary disk space requirement for queries that require sorts.
Partitioning can control how data is spread across physical devices. To balance I/O utilization, you can specify where to store the partitions of a table or index.
With this level of location control, you can accommodate the special needs of applications that require fast response time by reducing disk contention and using faster devices. On the other hand, data that is accessed infrequently, such as old historical data, can be moved to slow disks or stored in subsystems that support a storage hierarchy.
Disk striping and partitioning are both tools that can improve performance through the reduction of contention for disk arms. Which tool to use, or in which proportions to use them together, is an important issue to consider when physically designing databases. These issues should be considered not only with respect to performance, but also with respect to availability and partition independence.
Figure 9-2 shows the two extremes of combining partitioning and striping. Both (a) and (b) show four partitions spread across eight disks, but (a) stripes each partition onto its own pair of disks, whereas (b) stripes each partition onto all eight disks.
Intermediate configurations are also possible, where subsets of partitions are striped over subsets of disks.
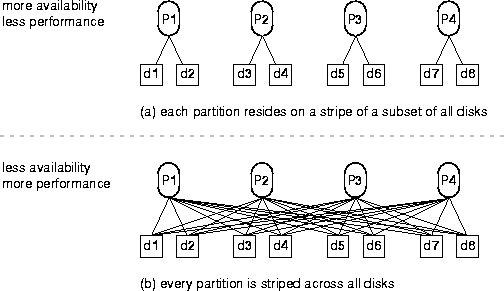
The trade-off between performance and availability must be decided when determining how to partition tables and indexes, and how to stripe the disks on which they are stored.
For mission-critical databases it is recommended that partition independence and availability be favored, therefore each partition that you want to stripe across disks should be striped onto its own set of disk drives, which should include enough drives to achieve the required I/O parallelism for accesses to that partition.
The vast majority of application programs require partition transparency, that is the programs should be insensitive to whether the data they access is partitioned and how it is partitioned.
A few application programs, however, can take advantage of partitions by explicitly requesting access to an individual partition, rather than the entire table. For example, a user might want to break a long batch job on a very large table into a sequence of short nightly batch jobs on individual partitions.
Instead of using partitioned tables, you can build separate tables with identical templates and define a view that does a UNION of these tables. This is known as manual partitioning, and the view is known as a partition view.
Partition views were the only form of partitioning available in Oracle7 Release 7.3. They are not recommended for new applications in Oracle8. Partition views that were created for Oracle7 databases can be converted to partitioned tables by using the EXCHANGE PARTITION option of the ALTER TABLE command.
|
Additional Information:
See Oracle8 Migration and the Oracle8 Administrator's Guide for instructions on converting partition views to partitioned tables. |
The basic idea behind partition views is to divide the large table into multiple physical tables using a partitioning criterion (a WHERE clause or CHECK constraint), then glue the smaller tables together into a whole with a UNION ALL view. You can then define sets of "base indexes" with identical key specifications on the base tables, which provide indexing capabilities when the UNION ALL view is used. Partition views must be indexed to work properly.
Queries that use a key range to select from a partition view access only the base tables that lie within the key range. The optimizer can use separate execution plans for a partition view's base tables. (In contrast, the optimizer uses a single execution plan for all partitions in a partitioned table.)
Manual partitioning with partition views has a number of disadvantages:
The database administrator is responsible for correctly defining the base tables and indexes that correspond to partitions, and for maintaining these definitions. The equivalent of DDL operations that move data across partitions (split, move, and so on) must be implemented via Export/Import or SQL scripts.
Some SQL operations must be performed using the base tables rather than the UNION ALL view. For example, INSERT refers to a base table, and user code is needed to obtain the table name that appears in an INSERT statement.
Some SQL operations on the UNION ALL view may perform badly because the optimizer does not take advantage of all the existing base indexes.
A SQL compiled query operating on a UNION ALL view internally replicates descriptive information for all tables that support the view.
Global indexes and referential integrity constraints cannot be defined on the UNION ALL view.
It is not possible to perform direct loads on a UNION ALL view.
Partitioning is specified with options to the CREATE TABLE and CREATE INDEX statements. After creating a partitioned table or index, you can use ALTER TABLE or ALTER INDEX statements to modify its partitioning attributes. The partitioning syntax for CREATE TABLE and CREATE INDEX statements is very similar.
The CREATE TABLE statement specifies:
Each partition description includes a clause defining supplemental, partition-level information about the algorithm used to map rows to partitions. This clause can also specify a partition name and physical attributes for the partition.
For partitioned tables, the logical attributes have additional restrictions. Partitioned tables cannot have any columns with LONG or LONG RAW datatypes, LOB datatypes (BLOB, CLOB, NCLOB, or BFILE), or object types.
If a table (or index) is partitioned on a column that has the DATE datatype, its partition descriptions should use the TO_DATE format mask; otherwise partition pruning is not possible. See "The TO_DATE Format Mask" on page 9-16.
You can create bitmap indexes on partitioned tables, with the restriction that the bitmap indexes must be local to the partitioned table - they cannot be global indexes. (See "Index Partitioning" on page 9-22.)
The cost based optimizer is used when a SQL statement accesses partitioned tables or indexes; rule base optimization is not available for partitions. A single execution plan is used for all partitions of a partitioned table.
Statistics can be gathered by partition, using the ANALYZE command. It is important to gather statistics whenever the nature of the data in a partitioned table changes significantly. The statistics can be found in these data dictionary views:
Range partitioning maps rows to partitions based on ranges of column values. Range partitioning is defined by the partitioning specification for a table or index:
PARTITION BY RANGE ( column_list )
and by the partitioning specifications for each individual partition:
VALUES LESS THAN ( value_list )
where:
In the ith partition, all rows (or rows pointed to by index entries) have partitioning keys that compare less than the partition bound for that partition. Unless the ith partition is the first partition in the table or index, all of the partitioning keys in the ith partition also compare greater than or equal to the partition bound for the (i-1)th partition. (See "Partition Bounds and Partitioning Keys" on page 9-14 for more information about how partitioning keys are compared to partition bounds, and in particular how multicolumn partitioning keys are handled.)
For example, in the following table of four partitions (one for each quarter's sales), a row with sale_year=1997, sale_month=7, and sale_day=18 has partitioning key (1997, 7, 18), belongs in the third partition, and would be stored in tablespace tsc. A row with sale_year=1997, sale_month=7, and sale_day=1 has partitioning key (1997, 7, 1), and also belongs in the third partition, stored in tablespace tsc.
CREATE TABLE sales ( invoice_no NUMBER, sale_year INT NOT NULL, sale_month INT NOT NULL, sale_day INT NOT NULL ) PARTITION BY RANGE (sale_year, sale_month, sale_day) ( PARTITION sales_q1 VALUES LESS THAN (1994, 04, 01) TABLESPACE tsa, PARTITION sales_q2 VALUES LESS THAN (1994, 07, 01) TABLESPACE tsb, PARTITION sales_q3 VALUES LESS THAN (1994, 10, 01) TABLESPACE tsc, PARTITION sales_q4 VALUES LESS THAN (1995, 01, 01) TABLESPACE tsd );
Every partition has a name, which must conform to the usual rules for naming schema objects and their parts. In particular:
You can rename a partition; however, you cannot create any synonyms on a partition name.
|
Additional Information:
See Oracle8 SQL Reference for information about the rules for naming schema objects. |
Partition names can optionally be referenced in DDL and DML statements and in utility statements like Import/Export and SQL*Loader. They always appear in context with the name of their parent table or index and they are never qualified by a schema name. (The schema name can be used to qualify the parent table or index.)
For example:
ALTER TABLE admin.patient_visits DROP PARTITION pv_dec92
See "SQL Extension: Partition-Extended Table Name" on page 9-42 for more information about referencing partitions in SQL statements.
This section describes how a row's partitioning key is compared with a set of upper and lower bounds to determine which partition the row belongs in.
Every table and index partition has a non-inclusive upper bound, which is specified by the VALUES LESS THAN clause. Every partition except the first partition also has a lower bound (inclusive), which is specified by the VALUES LESS THAN on the next-lower partition.
The partition bounds collectively define an ordering of the partitions in a table or index. The "first" partition is the partition with the lowest VALUES LESS THAN clause, and the "last" or "highest" partition is the partition with the highest VALUES LESS THAN clause.
If you attempt to insert a row into a table and the row's partitioning key is greater than or equal to the partition bound for the highest partition in the table, the insert will fail.
A partitioning key consists of an ordered list of up to 16 columns. A row's partitioning key is an ordered list of its values for the partitioning columns.
A partitioning key may not contain the LEVEL, ROWID, or MLSLABEL pseudocolumn or a column of type ROWID.
When comparing character values in partitioning keys and partition bounds, characters are compared according to their binary values. However, if a character consists of more than one byte, Oracle compares the binary value of each byte, not of the character.
The comparison also uses the comparison rules associated with the column data type (for example, blank-padded comparison is done for the ANSI CHAR data type). The NLS parameters, specifically the initialization parameters NLS_SORT and NLS_LANGUAGE and the environment variable NLS_LANG, have no effect on the comparison.
You can specify the keyword MAXVALUE for any value in the partition bound value_list. This keyword represents a virtual "infinite" value that sorts higher than any other value for the data type, including the null value.
For example, you might partition the office table on state (a CHAR(10) column) into three partitions with the following partition bounds:
NULL cannot be specified as a value in a partition bound value_list. An empty string also cannot be specified as a value in a partition bound value_list, because it is treated as NULL within the database server.
For the purpose of assigning rows to partitions, Oracle sorts nulls greater than all other values except MAXVALUE. Nulls sort less than MAXVALUE.
This means that if a table is partitioned on a nullable column, and the column is to contain nulls, then the highest partition should have a partition bound of MAXVALUE for that column. Otherwise the rows that contain nulls will map above the highest partition in the table and the insert will fail.
If the partition key includes a column that has the DATE datatype, you must specify partition bounds using the TO_DATE() format mask; otherwise partition elimination ("pruning") will not work.
For example, you might create the sales table using a DATE column:
CREATE TABLE sales ( invoice_no NUMBER, sale_date DATE NOT NULL ) PARTITION BY RANGE (sale_date) ( PARTITION sales_q1 VALUES LESS THAN (TO_DATE(`94-04-01','YY-MM-DD')) TABLESPACE tsa, PARTITION sales_q2 VALUES LESS THAN (TO_DATE(`94-07-01','YY-MM-DD')) TABLESPACE tsb, PARTITION sales_q3 VALUES LESS THAN (TO_DATE(`94-10-01','YY-MM-DD')) TABLESPACE tsc, PARTITION sales_q4 VALUES LESS THAN (TO_DATE(`95-01-01','YY-MM-DD')) TABLESPACE tsd );
You also need to use the TO_DATE() format mask when you query or modify data in the sales table, for example:
SELECT * FROM sales WHERE sale_date < TO_DATE(`94-06-15','YY-MM-DD');
When a table or index is partitioned on multiple columns, each partition bound and partitioning key is a list (or vector) of values. In this case, the keys are ordered according to ANSI SQL2 vector comparison rules (this is also the way multicolumn index keys are ordered in Oracle).
For vectors V1 and V2 which contain the same number of values, Vx[i] is the ith value in Vx. Assuming that V1[i] and V2[i] have compatible data types:
That is, if you want to know if a partitioning key PK is less than or equal to partition bound PB, you compare corresponding values in PK and PB until you find a pair that is not equal and that pair decides.
For example, if the partition bound for partition P is (7, 5, 10) and the partition bound for the next lowest partition is (6, 7, 3) then:
If MAXVALUE appears as an element of a partition bound value_list, then the values of all the following elements are irrelevant. For example, a partition bound of (10, MAXVALUE, 5) is equivalent to a partition bound of (10, MAXVALUE, 6) or to a partition bound of (10, MAXVALUE, MAXVALUE).
Multicolumn partitioning keys are useful when the primary key for the table contains multiple columns, but rows are not distributed evenly over the most significant column in the key. For example, suppose that the supplier_parts table contains information about which suppliers provide which parts, and the primary key for the table is (suppnum, partnum). It is not sufficient to partition on suppnum because some suppliers provide hundreds of thousands of parts, while others provide only a few specialty parts. Instead, you can partition the table on (suppnum, partnum).
Multicolumn partitioning keys are also useful when you represent a date as three CHAR columns instead of a DATE column.
If you specify a partition bound other than MAXVALUE for the highest partition in a table, this imposes an implicit CHECK constraint on the table. This constraint is not recorded in the data dictionary (but the partition bound itself is recorded).
Two tables or indexes are equipartitioned if they have identical logical partitioning attributes. They do not have to be the same type of schema object; for example, a table and an index can be equipartitioned.
If A and B are partitioned tables or indexes, where A[i] is the ith partition in A and B[i] is the ith partition in B, then A and B are equipartitioned if all of the following are true:
If Apcol[i] is the ith partitioning column in A and Bpcol[i] is the ith partitioning column in B, then the following must also be true:
A[i] and B[i] may differ in their physical attributes; in particular they do not have to reside in the same tablespace.
Equipartitioning is important to consider when designing the database.
Figure 9-3 shows four logically related schema objects that are equipartitioned:
The logical relationship between the four schema objects is shown on the left in Figure 9-3; the physical partitioning is shown on the right. (Triangles represent indexes and rectanges represent tables.)

This section describes the rules for creating partitioned tables and indexes and the physical attributes of partitions.
The rules for partitioning tables are simple:
Default physical attributes are initially specified when the CREATE TABLE statement creates a partitioned table. Since there is no segment corresponding to the partitioned table itself, these attributes will only be used in derivation of physical attributes of member partitions. Default physical attributes can later be modified using ALTER TABLE MODIFY DEFAULT ATTRIBUTES.
Physical attributes of table partitions created by CREATE TABLE and ALTER TABLE ADD PARTITION are determined as follows:
Physical attributes of an existing table partition may be modified by ALTER TABLE MOVE PARTITION and ALTER TABLE MODIFY PARTITION. Resulting attributes are determined as follows:
Physical attributes of table partitions created by ALTER TABLE SPLIT PARTITION are determined as follows:
Physical attributes of all partitions of a table may be modified by ALTER TABLE, for example, ALTER TABLE tablename NOLOGGING changes the logging mode of all partitions of tablename to NOLOGGING.
The rules for partitioning indexes are similar to those for tables:
However, partitioned indexes are more complicated than partitioned tables because there are four types of range-partitioned indexes: local prefixed, local non-prefixed, global prefixed, and global non-prefixed. These types are described below. Oracle supports three of the four types (global non-prefixed indexes are not useful in real applications).
In a local index, all keys in a particular index partition refer only to rows stored in a single underlying table partition. A local index is created by specifying the LOCAL attribute.
Oracle constructs the local index so that it is equipartitioned with the underlying table. Oracle range-partitions the index on the same columns as the underlying table, creates the same number of partitions, and gives them the same partition bounds as corresponding partitions of the underlying table. Oracle also maintains the index partitioning automatically as partitions in the underlying table are added, dropped, or split. This ensures that the index remains equipartitioned with the table.
Equipartitioning a table and its index has the following advantages:
A local index is prefixed if it is partitioned on a left prefix of the index columns.
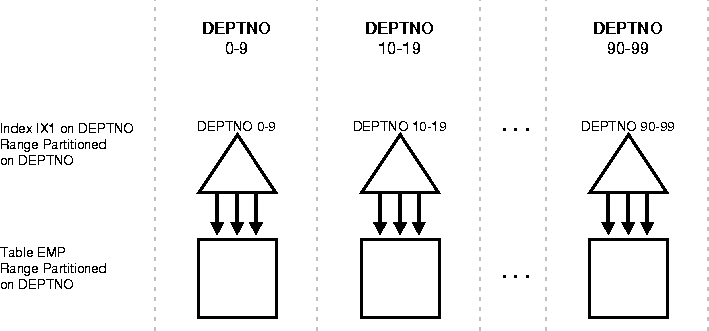
For example, if the sales table and its local index sales_ix are partitioned on the week_num column, then index sales_ix is local prefixed if it is defined on the columns (week_num,xaction_num). On the other hand, if index sales_ix is defined on column product_num then it is not prefixed.
Figure 9-4 shows another example of a local prefixed index.
Local prefixed indexes can be unique or non-unique.
A local index is non-prefixed if it is not partitioned on a left prefix of the index columns.
You cannot have a unique local non-prefixed index unless the index key is a subset of the partitioning key.
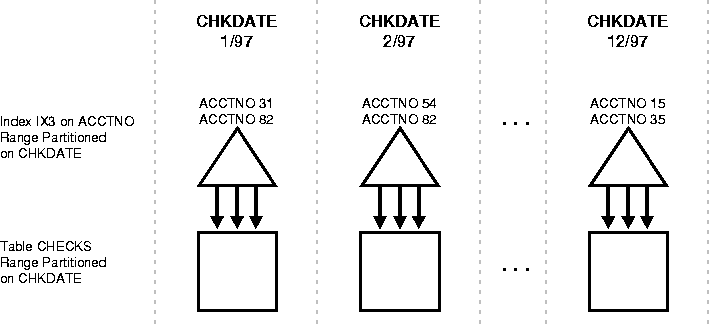
Figure 9-5 shows an example of a local non-prefixed index.
In a global index, the keys in a particular index partition may refer to rows stored in more than one underlying table partition. A global index is created by specifying the GLOBAL attribute (this is the default). The user is responsible for defining the initial partitioning of a global index at creation and for maintaining the partitioning over time. Index partitions can be dropped or split as necessary.
Normally, a global index is not equipartitioned with the underlying table. There is nothing to prevent an index from being equipartitioned with the underlying table, but Oracle does not take advantage of the equipartitioning when generating query plans or executing partition maintenance operations. So an index that is equipartitioned with the underlying table should be created as LOCAL.
A global index contains (conceptually) a single B*-tree with entries for all rows in all partitions. Each index partition may contain keys that refer to many different partitions in the table.
The highest partition of a global index must have a partition bound all of whose values are MAXVALUE. This insures that all rows in the underlying table can be represented in the index.
A global index is prefixed if it is partitioned on a left prefix of the index columns. (See Figure 9-6 for an example.) A global index is non-prefixed if it is not partitioned on a left prefix of the index columns. Oracle does not support global non-prefixed indexes.
Global prefixed indexes can be unique or non-unique.
Global indexes are harder to manage than local indexes:
Non-partitioned indexes are treated as global prefixed indexes.
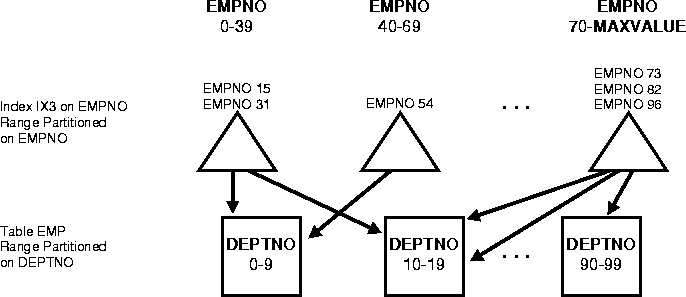
Table 9-1 summarizes the three types of partitioned indexes that Oracle supports.
| Type of Index | Index Equipartitioned with Table | Index Partitioned on Left Prefix of Index Columns | UNIQUE Attribute Allowed | Example | ||
|---|---|---|---|---|---|---|
|
Table Par-titioned On Column |
Index Columns |
Index Par-titioned On Column | ||||
|
Local Prefixed |
Yes |
Yes |
Yes |
A |
A,B |
A |
|
Local Non-Prefixed |
Yes |
No |
Yes1 |
A |
B |
A |
|
Global Prefixed |
No2 |
Yes |
Yes |
A |
B |
B |
|
Global Non-Prefixed3 |
- |
- |
- |
- |
- |
- |
Non-prefixed indexes are particularly useful in historical databases. In a table containing historical data it is common for an index to be defined on one column to support the requirements of fast access by that column, but partitioned on another column (the same column as the underlying table) to support the time interval for rolling out old data and rolling in new data.
Consider the sales table presented in Figure 9-1 ("SALES Table Partitioned by Week" on page 9-3). It contains a year's worth of data, divided into 13 partitions. It is range partitioned on week_no, four weeks to a partition. You might create a non-prefixed local index sales_ix on sales. The sales_ix index is defined on acct_no because there are queries that need fast access to the data by account number. However it is partitioned on week_no to match the sales table. Every four weeks the oldest partitions of sales and sales_ix are dropped and new ones are added.
It is more expensive to scan a non-prefixed index than to scan a prefixed index.
If an index is prefixed (either local or global) and Oracle is presented with a predicate involving the index columns, then partition pruning can restrict application of the predicate to a subset of the index partitions.
For example, in Figure 9-4 ("Local Prefixed Index" on page 9-24) if the predicate is DEPTNO=15, the optimizer knows to apply the predicate only to the second partition of the index. (If the predicate involves a bind variable, the optimizer will not know exactly which partition but it may still know there is only one partition involved, in which case at run time only one index partition will be accessed.)
When an index is non-prefixed Oracle often has to apply a predicate involving the index columns to all N index partitions. This is required to look up a single key, or to do an index range scan. For a range scan, Oracle must also combine information from N index partitions. For example, in Figure 9-5 ("Local Non-Prefixed Index" on page 9-25) a local index is partitioned on CHKDATE with an index key on ACCTNO. If the predicate is ACCTNO=31, Oracle probes all 12 index partitions.
Of course, if there is also a predicate on the partitioning columns then multiple index probes might not be necessary. Oracle takes advantage of the fact that a local index is equipartitioned with the underlying table to prune partitions based on the partition key. For example, if the predicate in Figure 9-5 is CHKDATE<3/97, Oracle only has to probe two partitions.
So for a non-prefixed index, if the partition key is a part of the WHERE clause (but not of the index key) the optimizer determines which index partitions to probe based on the underlying table partition.
When many queries and DML statements using keys of local, non-prefixed, indexes have to probe all index partitions, this effectively reduces the degree of partition independence provided by such indexes.
When deciding how to partition indexes on a table, you must consider the mix of applications that need to access the table. There is a trade-off between performance on the one hand and availability and manageability on the other.
Here are some of the guidelines you should consider:
For example, a query using the predicate "ACCTNO between 40 and 45" on the table CHECKS of Figure 9-5 ("Local Non-Prefixed Index" on page 9-25) causes parallel scans of all the partitions of the non-prefixed index IX3. On the other hand, a query using the predicate "DEPTNO between 40 and 45" on the table DEPTNO of Figure 9-4 ("Local Prefixed Index" on page 9-24) cannot be parallelized because it accesses a single partition of the prefixed index IX1.
Default physical attributes are initially specified when a CREATE INDEX statement creates a partitioned index. Since there is no segment corresponding to the partitioned index itself, these attributes are only used in derivation of physical attributes of member partitions. Default physical attributes can later be modified using ALTER INDEX.
Physical attributes of partitions created by CREATE INDEX are determined as follows:
Physical attributes (other than TABLESPACE, as explained above) of partitions of local indexes created in the course of processing ALTER TABLE ADD PARTITION are set to the default physical attributes of each index.
Physical attributes (other than TABLESPACE, as explained above) of index partitions created by ALTER TABLE SPLIT PARTITION are determined as follows:
Physical attributes of an existing index partition can be modified by ALTER INDEX MODIFY PARTITION and ALTER INDEX REBUILD PARTITION. Resulting attributes are determined as follows:
Physical attributes of global index partitions created by ALTER INDEX SPLIT PARTITION are determined as follows:
Physical attributes of all partitions of an index may be modified by ALTER INDEX, for example, ALTER INDEX indexname NOLOGGING changes the logging mode of all partitions of indexname to NOLOGGING.
DML table locks synchronize DML statements (INSERT, UPDATE, and DELETE) with DDL statements and LOCK TABLE statements. DML table locks also synchronize DDL and LOCK TABLE statements among themselves.
In order to provide partition independence for DDL and utility operations, Oracle supports DML partition locks. Partition independence allows you to perform DDL and utility operations on selected partitions without quiescing activity on other partitions.
The purpose of a partition lock is to protect the data in an individual partition while multiple users are accessing that partition or other partitions in the table concurrently.
Partition locks fall between table locks and row locks in the DML locking hierarchy, as shown in Figure 9-7.

Partition locks can be acquired in the same modes as table locks: Share (S), Exclusive (X), Row Share (SS), Row Exclusive (SX), and Share Row Exclusive (SSX).
Introducing an extra level of DML locking may affect the performance of short transactions in the Oracle Parallel Server environment because extra messages are sent to the Distributed Lock Manager.
To improve performance in the Oracle Parallel Server environment, you can turn off DML locking on selected tables with the ALTER TABLE DISABLE TABLE LOCK statement, which disables both table and partition DML locks. DDL statements are not allowed when DML locking is disabled.
This section covers the following topics:
For the purposes of this chapter, a maintenance operation is a DDL statement or a utility (like Export, Import, SQL*Loader) that alters the definition of a table or index and/or does bulk load or unload of data.
Most maintenance operations on non-partitioned tables and indexes also work on partitioned tables and indexes. For example, DROP TABLE can drop a partitioned table, and Export can export a partitioned table. However, some maintenance operations must be performed on individual partitions rather than the whole partitioned table or index. For example, ALTER TABLE ALLOCATE EXTENT cannot be used for a partitioned table; instead, you use ALTER TABLE MODIFY PARTITION ALLOCATE EXTENT for the partition or partitions that need new extents.
Maintenance operations are considered fast if their expected duration is not affected by the size (number of records) of the schema objects they operate upon. Fast maintenance operations result only in dictionary and segment header changes, and do not cause data scans and data updates. They are expected to complete in a short time (order of seconds). For example, RENAME is a fast operation while CREATE INDEX is not a fast operation.
A partition maintenance operation modifies one partition of a partitioned table or index. For example, you might add a new partition to an existing table, or you might move a partition to a different tablespace for better I/O load balancing, or you might load a partition.
Some partition maintenance operations are planned events. For example, in a historical database, the database administrator (DBA) periodically drops the oldest partitions from the database and adds a set of new partitions. This drop and add operation occurs on a regularly scheduled basis. Another example of a planned maintenance operation is a periodic Export/Import to recluster data and reduce fragmentation.
Other partition maintenance operations are unplanned events, required to recover from application or system problems. For example, unexpected transaction activity may force the DBA to split a partition to rebalance I/O load, or the DBA may need to rebuild one or more index partitions.
The partition maintenance operations are:
The concurrency model described in this section defines when it is possible to run more than one DDL and utility operation on the same schema object at the same time. It also defines which query and DML operations can be run concurrently with DDL and utility operations.
The model applies to all DDL statements. It also applies to utilities like SQL*Loader.
There are two types of maintenance operations, one-step and three-step.
One-step operations:
Three-step operations:
Finally, some operations may follow either one-step or three-step protocol:
If the table being altered has no global indexes defined on it, or if it is referenced by enabled referential constraints, statements in this group execute using the one-step protocol and they are fast. Otherwise, they execute using the three-step protocol. In the latter case the base table is locked in Row Exclusive (SX) mode and the partition is locked in Exclusive (X) mode.
If the partition to be split is USABLE, the statement follows the 3-step protocol, and partitions resulting from SPLIT are USABLE. If, on the other hand, the partition being split is UNUSABLE, the operation follows the 1-step protocol, and resulting partitions are also marked UNUSABLE.
If the partition to be dropped is USABLE, the statement follows the three-step protocol; otherwise it follows the one-step protocol.
Conventional Path SQL*Loader and Import use SQL INSERT so they are classified as DML operations for the purposes of the model. Export uses SQL SELECT so it is classified as a query operation.
The rules in this section can be derived from the definitions of one-step and three-step operations.
While a one-step operation is in progress:
Since queries (READ operations) do not take DML locks, queries are allowed on a partition which is being SPLIT or MOVEd while the SPLIT or MOVE is being processed. However, the current segments are dropped at the end of the operation, and the space may be reused. An error is signalled if the space is reused.
While an ALTER TABLE MOVE PARTITION, ALTER TABLE SPLIT PARTITION, ALTER TABLE EXCHANGE PARTITION, or Direct Path Load Table Partition is in progress on a partition:
While a CREATE INDEX or ALTER INDEX REBUILD PARTITION or ALTER INDEX DROP/SPLIT PARTIITON applied to a Usable partition (for a global index) is in progress:
While an ALTER INDEX REBUILD PARTITION (for a local index) is in progress on a partition which corresponds to an underlying table partition:
Some maintenance operations on a partition of a table cause the global indexes of the table or the index partitions to become Unusable. An example is ALTER TABLE MOVE PARTITION. The DBA has to run a script that includes global index rebuilds in addition to the partition maintenance operation. Consequently from a user point of view these operations serialize access to the entire table. Operations such as ALTER TABLE MOVE/SPLIT PARTITION make Unusable any non-partitioned global indexes as well as all partitions of partitioned global indexes.
Note that table partition operations which mark all partitions of global indexes also mark one partition of local index (the partition corresponding to the table partition being operated on) Unusable.
Similarly some partition maintenance operations require disabling Referential Integrity Constraints before the operation, and re-enabling them afterwards. An example is a ALTER TABLE DROP PARTITION of a non-empty partition. The DBA has to run a script that includes constraint re-enabling in addition to the partition maintenance operation. Consequently from a user point of view these operations serialize access to the entire table.
Queries whose execution starts before invocation of a partition maintenance operation, or before dictionary updates are done during a partition maintenance operation, correctly access via Consistent Read the data of the affected partitions as existing at query snapshot time. The behavior of such queries after dictionary updates have been done is unpredictable, in the sense that some of the data existing at snapshot time may be retrieved or errors may be returned.
Queries that use a partitioned index, and that start with some of the index partitions marked as Index Unusable, return an error when they actually access one of these partitions for the first time. This happens even if the partition has been made usable after query start.
Although many of the new DDL statements are partition-based, cursor invalidation is still table-based. This means that any DDL statement that modifies table T also invalidates all cursors that depend on T, even if the statement affects only one partition P of T and the cursors do not access partition P.
All partition maintenance operations can be run in recoverable (LOGGING) mode. However, some operations support a NOLOGGING option:
LOGGING is the default, except when the database is operating in NOARCHIVELOG mode. In that case, NOLOGGING is the default. DDL and utility statements that do not support the LOGGING/NOLOGGING option always run in recoverable mode (LOGGING).
|
Note: [NO]LOGGING is not an attribute of an operation but of a physical object. Hence, you cannot specify [NO]LOGGING in INSERT, but rather if you want to alter the logging mode of a table or index(es) involved in an INSERT, you need to issue ALTER TABLE/INDEX [NO]LOGGING before issuing the INSERT statement. For more information, see "Logging Mode" on page 21-5. |
You can always rename, change the physical storage attributes, or rebuild a partition of a local or global index. Changing how an index is partitioned must be handled differently depending on whether the index is local or global.
Oracle guarantees that the partitioning of a local index matches the partitioning of the underlying table. It does this by automatically creating or dropping index partitions as necessary when you alter the underlying table. You cannot explicitly add, drop, or split a partition in a local index.
For each local index:
Note that local index partitions produced as a result of splitting a parent table partition are marked Unusable if a corresponding table partition is non-empty.
When Oracle creates a new local index partition (via ADD or SPLIT):
The DBA is responsible for maintaining the partitioning of a global index. You can drop or split a partition in a global index. However, you cannot add a partition to a global index because the high partition of a global index always has a partition bound of MAXVALUE.
The ALTER INDEX REBUILD PARTITION statement can be used to regenerate a single partition in a local or global partitioned index. This saves you from having to perform DROP INDEX and then CREATE INDEX, which would affect all partitions in the index.
ALTER INDEX REBUILD PARTITION has four important applications:
Some maintenance operations mark indexes Index Unusable (IU). Index Unusable is an attribute of a non-partitioned index and of a partition in a partitioned index. When an index or index partition is marked IU, you get an error if you try to execute a SELECT or DML statement that requires the index (or partition).
When a single index partition is marked IU, you must rebuild the partition to make it valid again before using it. However, while one partition is marked IU the other partitions of the index are valid and you can execute SELECT or DML statements that require the index as long as the statements do not access the IU partition.
You can also split or rename the IU partition before rebuilding it, and you can drop an IU partition of a GLOBAL index.
When a non-partitioned index is marked IU, you can drop the indeYou can also drop an IU partition of a GLOBAL index.x and re-create it. You can also use ALTER INDEX REBUILD to rebuild a non-partitioned index.
Six types of maintenance operations can mark index partitions Index Unusable. In all cases, you must rebuild the index partitions when the operation is complete.
Privileges for partitions are granted on the parent table or index, not on individual partitions.
If a user or role has the privileges required to perform an Oracle operation on non-partitioned tables and indexes (including the necessary resource privileges), then the same Oracle operations are allowed on partitioned tables and indexes. For example:
If a user or role has the privileges required to perform an ALTER operation on a table or index, then the new ALTER operations on partitions of the table or index can be invoked, with these exceptions:
All of the ALTER TABLE PARTITION operations are audited just like ALTER TABLE operations. No new audit attributes are used for partitions.
Partition-level bulk operations are restricted to just the rows of a particular partition; for example, a user who wants to drop a partition without making all the global indexes UNUSABLE would want to delete all the rows from just that partition.
Such operations are very naturally expressed using the partition-extended table name syntax. Trying to phrase the same operation with a where-clause predicate becomes fairly cumbersome especially when the range partitioning key uses multiple columns.
The table specification syntax for the following DML statements may contain an optional partition specification for non-remote partitioned tables:
For example:
SELECT * FROM schema.table PARTITION part_name;
This syntax provides a simple way of viewing individual partitions as tables: A view can be created which selects from just one partition using the partition-extended table name, and this view can be used in lieu of a table.
With such views you can also build partition-level access control mechanisms by granting (revoking) privileges on these views to (from) other users or roles. For application portability and ANSI syntax compliance you may use views to insulate your applications from this Oracle proprietary extension.
The use of partition-extended table names has the following restrictions:
A partition-extended table name cannot contain a dblink or a synonym which translates to a table with a dblink. If you need to use remote partitions, you can create a view at the remote site which uses the partition-extended table name syntax and refer to that remote view.
A SQL statement using the partition-extended table name syntax cannot be used in a PL/SQL block, though it can be used through dynamic SQL via the DBMS_SQL package. Again, if you need to refer to a partition within a PL/SQL block you can instead use views which in turn use the partition-extended table name syntax.
A partition extension must be specified with a base table. No synonyms, views, or any other schema objects are allowed.
The following statements contain valid partition-extended table names:
SELECT * FROM sales PARTITION (nov95) s WHERE s.amount_of_sale > 1000; UPDATE sales PARTITION (feb96) s SET s.account_name = UPPER(s.account_name); DELETE FROM sales PARTITION (nov95) WHERE amount_of_sale != 0; INSERT INTO sales PARTITION (oct95) SELECT * FROM lastest_data; INSERT INTO sales PARTITION (oct95) VALUES (...); INSERT INTO sales PARTITION (oct95) (acct_no, ..., week_no) VALUES (...); LOCK TABLE sales PARTITION (jun95) IN EXCLUSIVE MODE; CREATE VIEW sales_feb96 AS SELECT * FROM sales PARTITION (feb96);