





![[*]](jump.gif) .
.
| better selectivity | Sometimes two or more columns, each with poor selectivity, can be combined in a composite index with good selectivity. |
| additional data storage | If all the columns selected by a query are in a composite index, Oracle can return these values from the index without accessing the table. |
CREATE INDEX comp_ind ON tab1(x, y, z);
These combinations of columns are leading portions of the index: X, XY, and XYZ. These combinations of columns are not leading portions of the index: YZ and Z.
Follow these guidelines for choosing columns for composite indexes:
To be sure that a SQL statement can use an access path that uses an index, be sure the statement contains a construct that makes such an access path available. If you are using the cost-based approach, you should also generate statistics for the index. Once you have made the access path available for the statement, the optimizer may or may not choose to use the access path, based on the availability of other access paths.
.Example
Consider these queries that select rows from a table based on the value of a single column:
SELECT * FROM tab1 WHERE col1 = 'A' SELECT * FROM tab1 WHERE col1 = 'B';
Assume that the values of the COL1 column are the letters A through Z. Assume also that the table has 1000 rows and that 75% of those rows have a COL1 value of 'A'. Each of the other letters appears in 1% of the rows.
Since the value 'A' appears in 75% of the tables rows, the first query is likely to be executed faster with a full table scan than with an index scan using an index on the COL1 column. Since the value 'B' appears in 1% of the rows, an index scan is likely to be faster than a full table scan for the second query. For these reasons, it is desirable to create an index to be used by the second query, but it is not desirable to use this index for the first query. However, the number of occurrences of each distinct column value is not available to the optimizer. The optimizer is likely to choose the same access path for both of these queries, despite the disparity in the percentage of the table's rows each returns.
For the best performance of these queries, create an index on TAB1.COL1 so that it can be used by the second query:
CREATE INDEX col1_ind ON tab1(col1);
Modify the WHERE clause of the first query so that it does not make available the access path that uses the COL1_IND index:
SELECT * FROM tab1 WHERE col1 || '' = 'A';
This change prevents the query from using the access path provided by COL1_IND. Index access paths are not available if the WHERE clause performs an operation or function on the indexed column. For this reason, the optimizer must choose a full table scan for this query.
Note: This change to the WHERE clause does not change the result of the condition, so it does not cause the query to return a different set of rows. For a column containing number or date data, you can achieve the same goal by modifying the WHERE clause condition so that the column value is added to 0.
Oracle always rounds up the HASHKEYS value that you specify to the nearest prime number to obtain the actual number of hash values. This rounding is designed to reduce collisions.
To enable cost-based optimization for a statement, collect statistics for the tables accessed by the statement and be sure the OPTIMIZER_MODE initialization parameter is set to its default value of CHOOSE.
You can also enable cost-based optimization in these ways:
.Oracle can generate statistics using these techniques:
Because of the time and space required for the computation of table statistics, it is usually best to perform an estimation with a 20% sample size for tables and clusters. For indexes, computation does not take up as much time or space, so it is best to perform a computation.
When you generate statistics for a table, column, or index, if the data dictionary already contains statistics for the analyzed object, Oracle updates the existing statistics with the new ones. Oracle invalidates any currently parsed SQL statements that access any of the analyzed objects. When such a statement is next executed, the optimizer automatically chooses a new execution plan based on the new statistics. Distributed statements issued on remote databases that access the analyzed objects use the new statistics when they are next parsed.
Some statistics are always computed, regardless of whether you specify computation or estimation. If you choose estimation and the time saved by estimating a statistic is negligible, Oracle computes the statistic.
You can generate statistics with the ANALYZE command.
Example
This example generates statistics for the EMP table and its indexes:
ANALYZE TABLE emp ESTIMATE STATISTICS;
Choosing a Goal for the Cost-Based Approach The execution plan produced by the optimizer can vary depending upon the optimizer's goal. Optimizing for best throughput is more likely to result in a full table scan rather than an indexed scan or a sort-merge join rather than a nested loops join. Optimizing for best response time is more likely to result in an index scan or a nested loops join.
For example, consider a join statement that can be executed with either a nested loops operation or a sort-merge operation. The sort-merge operation may return the entire query result faster, while the nested loops operation may return the first row faster. If the goal is best throughput, the optimizer is more likely to choose a sort-merge join. If the goal is best response time, the optimizer is more likely to choose a nested loops join.
Choose a goal for the optimizer based on the needs of your application:
.This statement changes the goal of the cost-based approach for your session to best response time:
ALTER SESSION SET OPTIMIZER_GOAL = FIRST_ROWS;
If you neither collect statistics nor add hints to your SQL statements, your statements will continue to use rule-based optimization. However, you should eventually migrate your existing applications to use the cost-based approach, because the rule-based approach will not be available in future versions of Oracle.
You can enable cost-based optimization on a trial basis simply by collecting statistics. You can then return to rule-based optimization by deleting them or by setting either the value of the OPTIMIZER_MODE initialization parameter or the OPTIMIZER_GOAL parameter of the ALTER SESSION command to RULE. You can also use this value if you want to collect and examine statistics for your data without using the cost-based approach.
Hints are suggestions that you give the optimizer for optimizing a SQL statement. Hints allow you to make decisions usually made by the optimizer. You can use hints to specify
You can send hints for a SQL statement to the optimizer by enclosing them in a comment within the statement. For more information on comments, see Chapter 2, "Elements of SQL", of the Oracle7 Server SQL Reference.
A statement block can have only one comment containing hints. This comment can only follow the SELECT, UPDATE, or DELETE keyword. The syntax diagrams show the syntax for hints contained in both styles of comments that Oracle supports within a statement block.
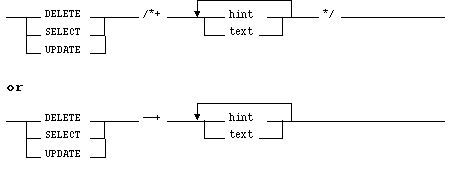
where:
| DELETE SELECT UPDATE | Is a DELETE, SELECT, or UPDATE keyword that begins a statement block. Comments containing hints can only appear after these keywords. |
| + | Is a plus sign that causes Oracle to interpret the comment as a list of hints. The plus sign must follow immediately after the comment delimiter (no space is permitted). |
| hint | Is one of the hints discussed in this section. If the comment contains multiple hints, each pair of hints must be separated by at least one space. |
| text | Is other commenting text that can be interspersed with the hints. |
The optimizer only recognizes hints when using the cost-based approach. If you include any hint (except the RULE hint) in a statement block, the optimizer automatically uses the cost-based approach.
The following sections show the syntax of each hint.
ALL_ROWS
The ALL_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best throughput (that is, minimum total resource consumption). For example, the optimizer uses the cost-based approach to optimize this statement for best throughput:
SELECT /*+ ALL_ROWS */ empno, ename, sal, job FROM emp WHERE empno = 7566;
FIRST_ROWS
The FIRST_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best response time (minimum resource usage to return first row). This hint causes the optimizer to make these choices:
SELECT /*+ FIRST_ROWS */ empno, ename, sal, job FROM emp WHERE empno = 7566;
The optimizer ignores this hint in DELETE and UPDATE statement blocks and in SELECT statement blocks that contain any of the following syntax:
If you specify either the ALL_ROWS or FIRST_ROWS hint in a SQL statement and the data dictionary contains no statistics about any of the tables accessed by the statement, the optimizer uses default statistical values (such as allocated storage for such tables) to estimate the missing statistics and subsequently to choose an execution plan. Since these estimates may not be as accurate as those generated by the ANALYZE command, you should use the ANALYZE command to generate statistics for all tables accessed by statements that use cost-based optimization.
If you specify hints for access paths or join operations along with either the ALL_ROWS or FIRST_ROWS hint, the optimizer gives precedence to the access paths and join operations specified by the hints.
CHOOSE
In the following statement, if statistics are present for the EMP table, the optimizer uses the cost-based approach. If no statistics for the EMP table exist in the data dictionary, the optimizer uses the rule-based approach.
SELECT /*+ CHOOSE */ empno, ename, sal, job FROM emp WHERE empno = 7566;
RULE
The RULE hint explicitly chooses rule-based optimization for a statement block. This hint also causes the optimizer to ignore any other hints specified for the statement block. For example, the optimizer uses the rule-based approach for this statement:
SELECT --+ RULE empno, ename, sal, job FROM emp WHERE empno = 7566;
The RULE hint, along with the rule-based approach, will not be available in future versions of Oracle.
You must specify the table to be accessed exactly as it appears in the statement. If the statement uses an alias for the table, you must use the alias, rather than the table name, in the hint. The name or alias must represent a table or a synonym for a table on your local database.
FULL
The FULL hint explicitly chooses a full table scan for the specified table. The syntax of the FULL hint is
FULL(table)
where table specifies the name or alias of the table on which the full table scan is to be performed.
For example, Oracle performs a full table scan on the ACCOUNTS table to execute this statement, even if there is an index on the ACCNO column that is made available by the condition in the WHERE clause:
SELECT /*+ FULL(a) Don't use the index on ACCNO */ accno, bal FROM accounts a WHERE accno = 7086854;
Note: Because the ACCOUNTS table has an alias, A, the hint must refer to the table by its alias, rather than by its name. Also, do not specify schema names in the hint, even if they are specified in the FROM clause.
ROWID
The ROWID hint explicitly chooses a table scan by ROWID for the specified table. The syntax of the ROWID hint is
ROWID(table)
where table specifies the name or alias of the table on which the table access by ROWID is to be performed.
CLUSTER
The CLUSTER hint explicitly chooses a cluster scan to access the specified table. The syntax of the CLUSTER hint is
CLUSTER(table)
where table specifies the name or alias of the table to be accessed by a cluster scan.
The following example illustrates the use of the CLUSTER hint.
SELECT --+ CLUSTER emp ename, deptno FROM emp, dept WHERE deptno = 10 AND emp.deptno = dept.deptno;
HASH
The HASH hint explicitly chooses a hash scan to access the specified table. The syntax of the HASH hint is
HASH(table)
where table specifies the name or alias of the table to be accessed by a hash scan.
INDEX
The INDEX hint explicitly chooses an index scan for the specified table. The syntax of the INDEX hint is

where:
| table | Specifies the name or alias of the table associated with the index to be scanned. |
| index | Specifies an index on which an index scan is to be performed. |
SELECT name, height, weight FROM patients WHERE sex = 'M';
Assume that there is an index on the SEX column and that this column contains the values M and F. If there are equal numbers of male and female patients in the hospital, the query returns a relatively large percentage of the table's rows and a full table scan is likely to be faster than an index scan. However, if a very small percentage of the hospital's patients are male, the query returns a relatively small percentage of the table's rows and an index scan is likely to be faster than a full table scan.
The number of occurrences of each distinct column value is not available to the optimizer. The cost-based approach assumes that each value has an equal probability of appearing in each row. For a column having only two distinct values, the optimizer assumes each value appears in 50% of the rows, so the cost-based approach is likely to choose a full table scan rather than an index scan.
If you know that the value in the WHERE clause of your query appears in a very small percentage of the rows, you can use the INDEX hint to force the optimizer to choose an index scan. In this statement, the INDEX hint explicitly chooses an index scan on the SEX_INDEX, the index on the SEX column:
SELECT /*+ INDEX(patients sex_index) Use SEX_INDEX, since there
are few male patients */
name, height, weight
FROM patients
WHERE sex = 'M';INDEX_ASC
The INDEX_ASC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, Oracle scans the index entries in ascending order of their indexed values. The syntax of the INDEX_ASC hint is

Each parameter serves the same purpose as in the INDEX hint.
Because Oracle's default behavior for a range scan is to scan index entries in ascending order of their indexed values, this hint does not currently specify anything more than the INDEX hint. However, since Oracle Corporation does not guarantee that the default behavior for an index range scan will remain the same in future versions of Oracle, you may want to use the INDEX_ASC hint to specify ascending range scans explicitly, should the default behavior change.
INDEX_DESC
The INDEX_DESC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, Oracle scans the index entries in descending order of their indexed values. The syntax of the INDEX_DESC is

Each parameter serves the same purpose as in the INDEX hint. This hint has no effect on SQL statements that access more than one table. Such statements always perform range scans in ascending order of the indexed values. For example, consider this table, which contains the temperature readings of a tank of water holding marine life:
CREATE TABLE tank_readings
(time DATE CONSTRAINT un_time UNIQUE,
temperature NUMBER );Each of the table's rows stores a time and the temperature measured at that time. A UNIQUE constraint on the TIME column ensures that the table does not contain more than one reading for the same time.
Oracle enforces this constraint with an index on the TIME column. Consider this complex query, which selects the most recent temperature reading taken as of a particular time T. The subquery returns either T or the latest time before T at which a temperature reading was taken. The parent query then finds the temperature taken at that time:
SELECT temperature
FROM tank_readings
WHERE time = (SELECT MAX(time)
FROM tank_readings
WHERE time <= TO_DATE(:t) );The execution plan for this statement looks like the following figure:
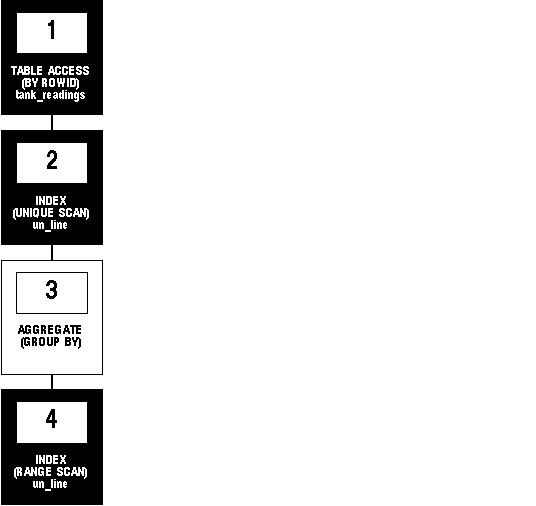 Figure 7 - 1. Execution Plan without Hints
Figure 7 - 1. Execution Plan without Hints
To execute this statement, Oracle performs these operations:
SELECT /*+ INDEX_DESC(tank_readings un_time) */ temperature
FROM tank_readings
WHERE time <= TO_DATE(:t)
AND ROWNUM = 1
ORDER BY time DESC;The execution plan for this query looks like the following figure:
 Figure 7 - 2. Execution Plan wile Using the INDEX_DESC Hint
Figure 7 - 2. Execution Plan wile Using the INDEX_DESC Hint
To execute this statement, Oracle performs these operations:
Since the default behavior is an ascending index scan, issuing this query without the INDEX_DESC hint would cause Oracle to begin scanning at the earliest time in the table, rather than at the latest time less than or equal to T. Step 1 would then return the temperature at the earliest time. You must use this hint to make this query return the same temperature as the complex query described earlier in this section.
AND_EQUAL
The AND_EQUAL hint explicitly chooses an execution plan that uses an access path that merges the scans on several single-column indexes. The syntax of the AND_EQUAL hint is:

where:
| table | Specifies the name or alias of the table associated with the indexes to be merged. |
| index | Specifies an index on which an index scan is to be performed. You must specify at least two indexes. You cannot specify more than five. |
The USE_CONCAT hint forces combined OR conditions in the WHERE clause of a query to be transformed into a compound query using the UNION ALL set operator. Normally, this transformation occurs only if the cost of the query using the concatenations is cheaper than the cost without them.
ORDERED
The ORDERED hint causes Oracle to join tables in the order in which they appear in the FROM clause. For example, this statement joins table TAB1 to table TAB2 and then joins the result to table TAB3:
SELECT /*+ ORDERED */ tab1.col1, tab2.col2, tab3.col3
FROM tab1, tab2, tab3
WHERE tab1.col1 = tab2.col1
AND tab2.col1 = tab3.col1;If you omit the ORDERED hint from a SQL statement performing a join, the optimizer chooses the order in which to join the tables.
You may want to use the ORDERED hint to specify a join order if you know something about the number of rows selected from each table that the optimizer does not. Such information would allow you to choose an inner and outer table better than the optimizer could.
The USE_NL and USE_MERGE hints must be used with the ORDERED hint. Oracle uses these hints when the referenced table is forced to be the inner table of a join, and they are ignored if the referenced table is the outer table.
USE_NL
The USE_NL hint causes Oracle to join each specified table to another row source with a nested loops join using the specified table as the inner table. The syntax of the USE_NL hint is

where table is the name or alias of a table to be used as the inner table of a nested loops join.
For example, consider this statement, which joins the ACCOUNTS and CUSTOMERS tables. Assume that these tables are not stored together in a cluster:
SELECT accounts.balance, customers.last_name, customers.first_name FROM accounts, customers WHERE accounts.custno = customers.custno;
Since the default goal of the cost-based approach is best throughput, the optimizer will choose either a nested loops operation or a sort-merge operation to join these tables, depending on which is likely to return all the rows selected by the query more quickly.
However, you may want to optimize the statement for best response time, or the minimal elapsed time necessary to return the first row selected by the query, rather than best throughput. If so, you can force the optimizer to choose a nested loops join by using the USE_NL hint. In this statement, the USE_NL hint explicitly chooses a nested loops join with the CUSTOMERS table as the inner table:
SELECT /*+ ORDERED USE_NL(customers) Use N-L to get first row faster */ accounts.balance, customers.last_name, customers.first_name FROM accounts, customers WHERE accounts.custno = customers.custno;
In many cases, a nested loops join returns the first row faster than a sort-merge join. A nested loops join can return the first row after reading the first selected row from one table and the first matching row from the other and combining them, while a sort-merge join cannot return the first row until after reading and sorting all selected rows of both tables and then combining the first rows of each sorted row source.
USE_MERGE
The USE_MERGE hint causes Oracle to join each specified table with another row source with a sort-merge join. The syntax of the USE_MERGE hint is
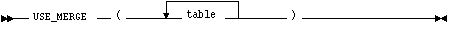
where table is a table to be joined to the row source resulting from joining the previous tables in the join order using a sort-merge join.
PARALLEL
The PARALLEL hint allows you to specify the desired number of concurrent query servers that can be used for the query. The syntax is

The PARALLEL hint must use the table alias if an alias is specified in the query. The PARALLEL hint can then take two values separated by commas after the table name. The first value specifies the degree of parallelism for the given table, the second value specifies how the table is to be split among the instances of a Parallel Server. Specifying DEFAULT or no value signifies the query coordinator should examine the settings of the initialization parameters (described in a later section) to determine the default degree of parallelism.
In the following example, the PARALLEL hint overrides the degree of parallelism specified in the EMP table definition:
SELECT /*+ FULL(scott_emp) PARALLEL(scott_emp, 5) */ ename FROM scott.emp scott_emp;
In the next example, the PARALLEL hint overrides the degree of parallelism specified in the EMP table definition and tells the optimizer to use the default degree of parallelism determined by the initialization parameters. This hint also specifies that the table should be split among all of the available instances, with the default degree of parallelism on each instance.
SELECT /*+ FULL(scott_emp) PARALLEL(scott_emp, DEFAULT,DEFAULT) */ ename FROM scott.emp scott_emp;
NOPARALEL
The NOPARALLEL hint allows you to disable parallel scanning of a table, even if the table was created with a PARALLEL clause. The following example illustrates the NOPARALLEL hint:
SELECT /*+ NOPARALLEL(scott_emp) */ ename FROM scott.emp scott_emp;
The NOPARALLEL hint is equivalent to specifying the hint /*+ PARALLEL(table,1,1) */.
CACHE
The CACHE hint specifies that the blocks retrieved for the table in the hint are placed at the most recently used end of the LRU list in the buffer cache when a full table scan is performed. This option is useful for small lookup tables. In the following example, the CACHE hint overrides the table's default caching specification:
SELECT /*+ FULL (scott_emp) CACHE(scott_emp) */ ename FROM scott.emp scott_emp;
NOCACHE
The NOCACHE hint specifies that the blocks retrieved for this table are placed at the least recently used end of the LRU list in the buffer cache when a full table scan is performed. This is the normal behavior of blocks in the buffer cache. The following example illustrates the NOCACHE hint:
SELECT /*+ FULL(scott_emp) NOCACHE(scott_emp) */ ename FROM scott.emp scott_emp;
PUSH_SUBQ
The hint will have no effect if the subquery is applied to a remote table or one that is joined using a merge join.
This example shows the execution plans for two SQL statements that perform the same function. Both statements return all the departments in the DEPT table that have no employees in the EMP table. Each statement searches the EMP table with a subquery. Assume there is an index, DEPTNO_INDEX, on the DEPTNO column of the EMP table.
This is the first statement and its execution plan:
SELECT dname, deptno
FROM dept
WHERE deptno NOT IN
(SELECT deptno FROM emp);
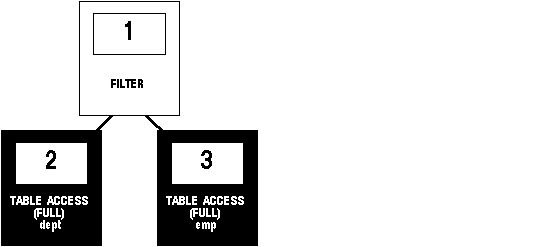 Figure 7 - 3. Execution Plan with Two Full Table Scans
Figure 7 - 3. Execution Plan with Two Full Table Scans
Step 3 of the output indicates that Oracle executes this statement by performing a full table scan of the EMP table despite the index on the DEPTNO column. This full table scan can be a time-consuming operation. Oracle does not use the index because the subquery that searches the EMP table does not have a WHERE clause that makes the index available.
However, this SQL statement selects the same rows by accessing the index:
SELECT dname, deptno
FROM dept
WHERE NOT EXISTS
(SELECT deptno
FROM emp
WHERE dept.deptno = emp.deptno);
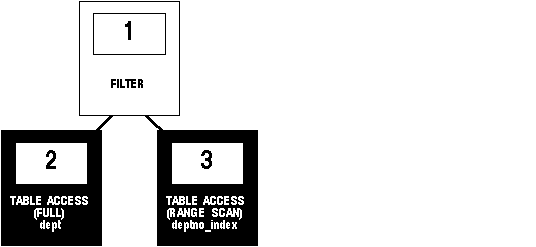 Figure 7 - 4. Execution Plan with a Full Table Scan and an Index Scan
Figure 7 - 4. Execution Plan with a Full Table Scan and an Index Scan
The WHERE clause of the subquery refers to the DEPTNO column of the EMP table, so the index DEPTNO_INDEX is used. The use of the index is reflected in Step 3 of the execution plan. The index range scan of DEPTNO_INDEX takes less time than the full scan of the EMP table in the first statement. Furthermore, the first query performs one full scan of the EMP table for every DEPTNO in the DEPT table. For these reasons, the second SQL statement is faster than the first.
If you have statements in your applications that use the NOT IN operator, as the first query in this example does, you should consider rewriting them so that they use the NOT EXISTS operator. This would allow such statements to use an index, if one exists.