





| evaluation of expressions and conditions | The optimizer first evaluates expressions and conditions containing constants as fully as possible. |
| statement transformation | For a complex statement involving, for example, correlated subqueries, the optimizer may transform the original statement into an equivalent join statement. |
| view merging | For a SQL statement that accesses a view, the optimizer often merges the query in the statement with that in the view and then optimizes the result. |
| choice of optimization approaches | The optimizer chooses either a rule-based or cost-based approach to optimization. |
| choice of access paths | For each table accessed by the statement, the optimizer chooses one or more of the available access paths to obtain the table's data. |
| choice of join orders | For a join statement that joins more than two tables, the optimizer chooses which pair of tables is joined first, and then which table is joined to the result, on so on. |
| choice of join operations | For any join statement, the optimizer chooses an operation to perform the join. |
| simple statements | A simple statement is an INSERT, UPDATE, DELETE, or SELECT statement that involves only a single table. |
| simple queries | A query is another name for a SELECT statement. |
| joins | A join is a query that selects data from more than one table. A join is characterized by multiple tables in the FROM clause. Oracle pairs the rows from these tables using the condition specified in the WHERE clause and returns the resulting rows. This condition is called the join condition and usually compares columns of all the joined tables. |
| equijoins | An equijoin is characterized by a join condition containing an equality operator. |
| nonequijoins | A nonequijoin is characterized by a join condition containing something other than an equality operator. |
| outer joins | An outer join is characterized by a join condition that uses the outer join operator (+) with one or more of the columns of one of the tables. Oracle returns all rows that meet the join condition. Oracle also returns all rows from the table without the outer join operator for which there are no matching rows in the table with the outer join operator. |
| cartesian products | A join with no join condition results in a cartesian product, or a cross product. A cartesian product is the set of all possible combinations of rows drawn one from each table. In other words, for a join of two tables, each row in one table is matched in turn with every row in the other. A cartesian product for more than two tables is the result of pairing each row of one table with every row of the cartesian product of the remaining tables. All other kinds of joins are subsets of cartesian products effectively created by deriving the cartesian product and then excluding rows that fail the join condition. |
| complex statements | A complex statement is an INSERT, UPDATE, DELETE, or SELECT statement that contains a form of the SELECT statement called a subquery. This is a query within another statement that produces a set of values for further processing within the statement The outer portion of the complex statement that contains a subquery is called the parent statement. |
| compound queries | A compound query is a query that uses set operators (UNION, UNION ALL, INTERSECT, or MINUS) to combine two or more simple or complex statements. Each simple or complex statement in a compound query is called a component query. |
| statements accessing views | You can also write simple, join, complex, and compound statements that access views as well as tables. |
| distributed statements | A distributed statement is one that accesses data on a remote database. |
Constants Any computation of constants is performed only once when the statement is optimized rather than each time the statement is executed. Consider these conditions that test for monthly salaries greater than 2000:
sal > 24000/12
sal > 2000
sal*12 > 24000
If a SQL statement contains the first condition, the optimizer simplifies it into the second condition.
Note that the optimizer does not simplify expressions across comparison operators. The optimizer does not simplify the third expression into the second. For this reason, application developers should write conditions that compare columns with constants whenever possible, rather than conditions with expressions involving columns.
LIKE The optimizer simplifies conditions that use the LIKE comparison operator to compare an expression with no wildcard characters into an equivalent condition that uses an equality operator instead. For example, the optimizer simplifies the first condition below into the second:
ename LIKE 'SMITH'
ename = 'SMITH'
The optimizer can simplify these expressions only when the comparison involves variable-length datatypes. For example, if ENAME was of type CHAR(10), the optimizer cannot transform the LIKE operation into an equality operation due to the comparison semantics of fixed-length datatypes.
IN The optimizer expands a condition that uses the IN comparison operator to an equivalent condition that uses equality comparison operators and OR logical operators. For example, the optimizer expands the first condition below into the second:
ename IN ('SMITH', 'KING', 'JONES')
ename = 'SMITH' OR ename = 'KING' OR ename = 'JONES'
ANY or SOME The optimizer expands a condition that uses the ANY or SOME comparison operator followed by a parenthesized list of values into an equivalent condition that uses equality comparison operators and OR logical operators. For example, the optimizer expands the first condition below into the second:
sal > ANY (:first_sal, :second_sal)
sal > :first_sal OR sal > :second_sal
The optimizer transforms a condition that uses the ANY or SOME operator followed by a subquery into a condition containing the EXISTS operator and a correlated subquery. For example, the optimizer transforms the first condition below into the second:
x > ANY (SELECT sal
FROM emp
WHERE job = 'ANALYST')
EXISTS (SELECT sal
FROM emp
WHERE job = 'ANALYST'
AND x > sal)
ALL The optimizer expands a condition that uses the ALL comparison operator followed by a parenthesized list of values into an equivalent condition that uses equality comparison operators and AND logical operators. For example, the optimizer expands the first condition below into the second:
sal > ALL (:first_sal, :second_sal)
sal > :first_sal AND sal > :second_sal
The optimizer transforms a condition that uses the ALL comparison operator followed by a subquery into an equivalent condition that uses the ANY comparison operator and a complementary comparison operator. For example, the optimizer transforms the first condition below into the second:
x > ALL (SELECT sal
FROM emp WHERE deptno = 10)
NOT (x <= ANY (SELECT sal
FROM emp WHERE deptno = 10) )
The optimizer then transforms the second query into the following query using the rule for transforming conditions with the ANY comparison operator followed by a correlated subquery:
NOT EXISTS (SELECT sal
FROM emp
WHERE deptno = 10 AND x <= sal)
BETWEEN The optimizer always replaces a condition that uses the BETWEEN comparison operator with an equivalent condition that uses the >= and <= comparison operators. For example, the optimizer replaces the first condition below with the second:
sal BETWEEN 2000 AND 3000
sal >= 2000 AND sal <= 3000
NOT The optimizer simplifies a condition to eliminate the NOT logical operator. The simplification involves removing the NOT logical operator and replacing a comparison operator with its opposite comparison operator. For example, the optimizer simplifies the first condition below into the second one:
NOT deptno = (SELECT deptno FROM emp WHERE ename = 'TAYLOR')
deptno <> (SELECT deptno FROM emp WHERE ename = 'TAYLOR')
Often a condition containing the NOT logical operator can be written many different ways. The optimizer attempts to transform such a condition so that the subconditions negated by NOTs are as simple as possible, even if the resulting condition contains more NOTs. For example, the optimizer simplifies the first condition below into the second and then into the third.
NOT (sal < 1000 OR comm IS NULL)
NOT sal < 1000 AND comm IS NOT NULL
sal >= 1000 AND comm IS NOT NULL
Imagine a WHERE clause containing two conditions of these forms:
WHERE column1 comp_oper constant
AND column1 = column2
In this case, the optimizer infers the condition
column2 comp_oper constant
where:
| comp_oper | Is any of the comparison operators =, !=, ^=, <, <>, <, >, <=, or >=. |
| constant | Is any constant expression involving operators, SQL functions, literals, bind variables, and correlation variables. |
Example
Consider this query in which the WHERE clause containing two conditions that each use the EMP.DEPTNO column:
SELECT *
FROM emp, dept
WHERE emp.deptno = 20
AND emp.deptno = dept.deptno;
Using transitivity, the optimizer infers this condition:
dept.deptno = 20
If there is an index on the DEPT.DEPTNO column, this condition makes available access paths using that index.
Note: The optimizer only infers conditions that relate columns to constant expressions, rather than columns to other columns. Imagine a WHERE clause containing two conditions of these forms:
WHERE column1 comp_oper column3
AND column1 = column2
In this case, the optimizer does not infer this condition:
column2 comp_oper column3
Example
Consider this query with a WHERE clause that contains two conditions combined with an OR operator:
SELECT *
FROM emp
WHERE job = 'CLERK'
OR deptno = 10;
If there are indexes on both the JOB and DEPTNO columns, the optimizer may transform the query above into the equivalent query below:
SELECT *
FROM emp
WHERE job = 'CLERK'
UNION ALL
SELECT *
FROM emp
WHERE deptno = 10
AND job <> 'CLERK';
If you are using the rule-based approach, the optimizer makes this transformation because each component query of the resulting compound query can be executed using an index. The rule-based approach assumes that executing the compound query using two index scans is faster than executing the original query using a full table scan.
If you are using the cost-based approach, the optimizer compares the cost of executing the original query using a full table scan with that of executing the resulting query when deciding whether to make the transformation. The execution plan for the transformed statement might look like this:
 To execute the transformed query, Oracle performs these steps:
To execute the transformed query, Oracle performs these steps:
Example
Consider this query and assume there is an index on the ENAME column:
SELECT *
FROM emp
WHERE ename = 'SMITH'
OR sal > comm;
Transforming the query above would result in the compound query below:
SELECT *
FROM emp
WHERE ename = 'SMITH'
UNION ALL
SELECT *
FROM emp
WHERE sal > comm;
Since the condition in the WHERE clause of the second component query (SAL > COMM) does not make an index available, the compound query requires a full table scan. For this reason, the optimizer does not consider making the transformation and chooses a full table scan to execute the original statement.
![[*]](jump.gif) .
.Consider this complex statement that selects all rows from the ACCOUNTS table whose owners appear in the CUSTOMERS table:
SELECT *
FROM accounts
WHERE custno IN
(SELECT custno FROM customers);
If the CUSTNO column of the CUSTOMERS table is a primary key or has a UNIQUE constraint, the optimizer can transform the complex query into this join statement that is guaranteed to return the same data:
SELECT accounts.*
FROM accounts, customers
WHERE accounts.custno = customers.custno;
The execution plan for this statement might look like the following figure:
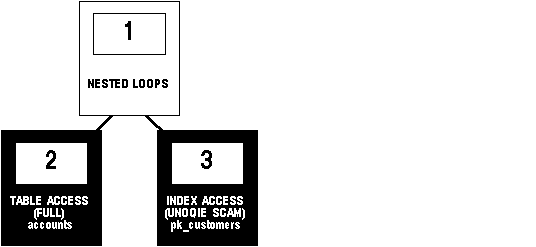 Figure 5 - 2. Execution Plan for a Nested Loops Join
Figure 5 - 2. Execution Plan for a Nested Loops Join
To execute this statement, Oracle performs a nested loops join operation. For information on nested loops joins, see the section "Join Operations" .
If the optimizer cannot transform a complex statement into a join statement, the optimizer chooses execution plans for the parent statement and the subquery as though they were separate statements. Oracle then executes the subquery and uses the rows it returns to execute the parent query.
Consider this complex statement that returns all rows from the ACCOUNTS table that have balances that are greater than the average account balance:
SELECT *
FROM accounts
WHERE accounts.balance >
(SELECT AVG(balance) FROM accounts);
There is no join statement that can perform the function of this statement, so the optimizer does not transform the statement. Note that complex queries whose subqueries contain group functions such as AVG cannot be transformed into join statements.
Merging the View's Query into the Accessing Statement To merge the view's query into the accessing statement, the optimizer replaces the name of the view with the name of its base table in the accessing statement and adds the condition of the view's query's WHERE clause to the accessing statement's WHERE clause.
Example
Consider this view of all employees who work in department 10:
CREATE VIEW emp_10
AS SELECT empno,ename, job, mgr, hiredate, sal, comm, deptno
FROM emp
WHERE deptno = 10;
Consider this query that accesses the view. The query selects the IDs greater than 7800 of employees who work in department 10:
SELECT empno
FROM emp_10
WHERE empno > 7800;
The optimizer transforms the query into the following query that accesses the view's base table:
SELECT empno
FROM emp
WHERE deptno = 10
AND empno > 7800;
If there are indexes on the DEPTNO or EMPNO columns, the resulting WHERE clause makes them available.
Merging the Accessing Statement into the View's Query The optimizer cannot always merge the view's query into the accessing statement. Such a transformation is not possible if the view's query contains
Example
Consider the TWO_EMP_TABLES view, which is the union of two employee tables. The view is defined with a compound query that uses the UNION set operator:
CREATE VIEW two_emp_tables
(empno, ename, job, mgr, hiredate, sal, comm, deptno) AS
SELECT empno, ename, job, mgr, hiredate, sal, comm, deptno FROM emp1 UNION
SELECT empno, ename, job, mgr, hiredate, sal, comm, deptno FROM emp2;
Consider this query that accesses the view. The query selects the IDs and names of all employees in either table who work in department 20:
SELECT empno, ename
FROM two_emp_tables
WHERE deptno = 20;
Since the view is defined as a compound query, the optimizer cannot merge the view query into the accessing query. Instead, the optimizer transforms the query by adding its WHERE clause condition into the compound query. The resulting statement looks like this:
SELECT empno, ename FROM emp1 WHERE deptno = 20
UNION
SELECT empno, ename FROM emp2 WHERE deptno = 20;
If there is an index on the DEPTNO column, the resulting WHERE clauses make it available.
Figure 5 - 3 shows the execution plan of the resulting statement.
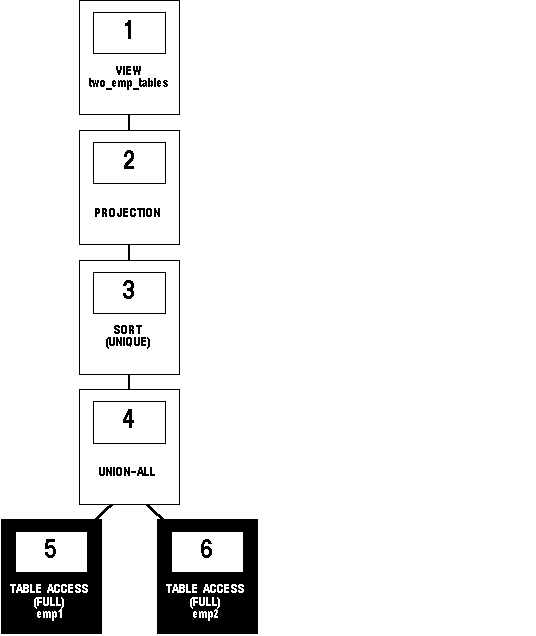 Figure 5 - 3. Accessing a View Defined with the UNION Set Operator
Figure 5 - 3. Accessing a View Defined with the UNION Set Operator
To execute this statement, Oracle performs these steps:
Consider the view EMP_GROUP_BY_DEPTNO, which contains the department number, average salary, minimum salary, and maximum salary of all departments that have employees:
CREATE VIEW emp_group_by_deptno
AS SELECT deptno,
AVG(sal) avg_sal,
MIN(sal) min_sal,
MAX(sal) max_sal
FROM emp
GROUP BY deptno;
Consider this query, which selects the average, minimum, and maximum salaries of department 10 from the EMP_GROUP_BY_DEPTNO view:
SELECT *
FROM emp_group_by_deptno
WHERE deptno = 10;
The optimizer transforms the statement by adding its WHERE clause condition into the view's query. The resulting statement looks like this:
SELECT deptno,
AVG(sal) avg_sal,
MIN(sal) min_sal,
MAX(sal) max_sal,
FROM emp
WHERE deptno = 10
GROUP BY deptno;
If there is an index on the DEPTNO column, the resulting WHERE clause makes it available.
Figure 5 - 4 shows the execution plan for the resulting statement. The execution plan uses an index on the DEPTNO column.
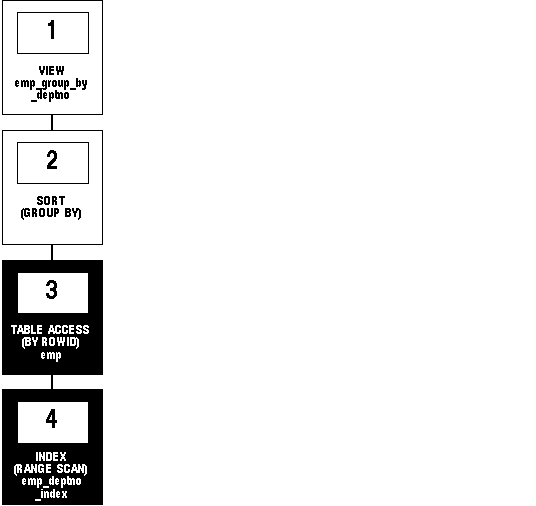 Figure 5 - 4. Accessing a View Defined with a GROUP BY Clause
Figure 5 - 4. Accessing a View Defined with a GROUP BY Clause
To execute this statement, Oracle performs these operations:
Consider this query, which accesses the EMP_GROUP_BY_DEPTNO view defined in the previous example. This query derives the averages for the average department salary, the minimum department salary, and the maximum department salary from the employee table:
SELECT AVG(avg_sal), AVG(min_sal), AVG(max_sal)
FROM emp_group_by_deptno;
The optimizer transforms this statement by applying the AVG group function to the select list of the view's query:
SELECT AVG(AVG(sal)), AVG(MIN(sal)), AVG(MAX(sal))
FROM emp
GROUP BY deptno;
Figure 5 - 5 shows the execution plan of the resulting statement:
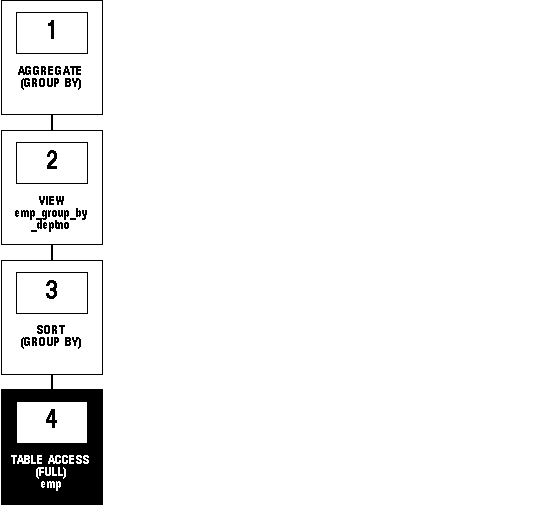 Figure 5 - 5. Applying Group Functions to a View Defined with a GROUP BY Clause
Figure 5 - 5. Applying Group Functions to a View Defined with a GROUP BY Clause
To execute this statement, Oracle performs these operations:
Example
Consider the EMP_GROUP_BY_DEPTNO view defined in the previous section:
CREATE VIEW emp_group_by_deptno
AS SELECT deptno,
AVG(sal) avg_sal, MIN(sal) min_sal,
MAX(sal) max_sal
FROM emp GROUP BY deptno;
Consider this query, which accesses the view. The query joins the average, minimum, and maximum salaries from each department represented in this view and to the name and location of the department in the DEPT table:
SELECT emp_group_by_deptno.deptno, avg_sal, min_sal, max_sal, dname, loc
FROM emp_group_by_deptno, dept WHERE emp_group_by_deptno.deptno = dept.deptno;
Since there is no equivalent statement that accesses only base tables, the optimizer cannot transform this statement. Instead, the optimizer chooses an execution plan that issues the view's query and then uses the resulting set of rows as it would the rows resulting from a table access.
Figure 5 - 6 shows the execution plan for this statement.
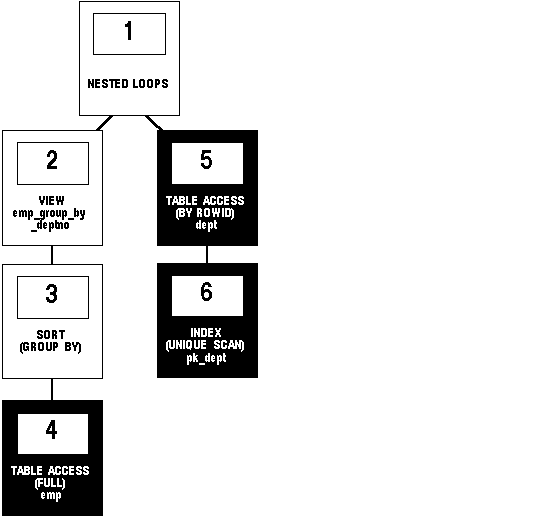 Figure 5 - 6. Joining a View Defined with a Group BY Clause to a Table
Figure 5 - 6. Joining a View Defined with a Group BY Clause to a Table
To execute this statement, Oracle performs these operations:
.
| CHOOSE | This value causes the optimizer to choose between the rule-based approach and the cost-based approach based on whether the statistics used for the cost-based approach are present. If the data dictionary contains statistics for at least one of the accessed tables, the optimizer uses the cost-based approach and optimizes with a goal of best throughput. If data dictionary contains no statistics for any of the accessed tables, the optimizer uses the rule-based approach. This is the default value for the parameter. |
| RULE | This value causes the optimizer to choose the rule-based approach for all SQL statements issued to the instance regardless of the presence of statistics. |
| ALL_ROWS | This value causes the optimizer to use the cost-based approach for all SQL statements in the session regardless of the presence of statistics and to optimize with a goal of best throughput (minimum resource usage to complete the entire statement). |
| FIRST_ROWS | This value causes the optimizer to use the cost-based approach for all SQL statements in the session regardless of the presence of statistics and to optimize with a goal of best response time (minimum resource usage to return the first row of the result set). |
| CHOOSE | This value causes the optimizer to choose between the rule-based approach and the cost-based approach based on whether the statistics used for the cost-based approach are present. If the data dictionary contains statistics for at least one of the accessed tables, the optimizer uses the cost-based approach and optimizes with a goal of best throughput. If the data dictionary contains no statistics for any of the accessed tables, the optimizer uses the rule-based approach. |
| ALL_ROWS | This value causes the optimizer to use the cost-based approach for all SQL statements in the session regardless of the presence of statistics and to optimize with a goal of best throughput (minimum resource usage to complete the entire statement). |
| FIRST_ROWS | This value causes the optimizer to use the cost-based approach for all SQL statements in the session regardless of the presence of statistics and to optimize with a goal of best response time (minimum resource usage to return the first row of the result set). |
| RULE | This value causes the optimizer to choose the rule-based approach for all SQL statements issued to the instance regardless of the presence of statistics. |
This section discusses these topics:
Full Table Scans A full table scan retrieves rows from a table. To perform a full table scan, Oracle reads all rows in the table, examining each row to determine whether it satisfies the statement's WHERE clause. Oracle reads every data block allocated to the table sequentially, so a full table scan can be performed very efficiently using multi-block reads. Oracle reads each data block only once.
Table Access by ROWID A table access by ROWID also retrieves rows from a table. The ROWID of a row specifies the datafile and data block containing the row and the location of the row in that block. Locating a row by its ROWID is the fastest way for Oracle to find a single row.
To access a table by ROWID, Oracle first obtains the ROWIDs of the selected rows, either from the statement's WHERE clause or through an index scan of one or more of the table's indexes. Oracle then locates each selected row in the table based on its ROWID.
Cluster Scans From a table stored in an indexed cluster, a cluster scan retrieves rows that have the same cluster key value. In an indexed cluster, all rows with the same cluster key value are stored in the same data blocks. To perform a cluster scan, Oracle first obtains the ROWID of one of the selected rows by scanning the cluster index. Oracle then locates the rows based on this ROWID.
Hash Scans Oracle can use a hash scan to locate rows in a hash cluster based on a hash value. In a hash cluster, all rows with the same hash value are stored in the same data blocks. To perform a hash scan, Oracle first obtains the hash value by applying a hash function to a cluster key value specified by the statement. Oracle then scans the data blocks containing rows with that hash value.
Index Scans An index scan retrieves data from an index based on the value of one or more columns of the index. To perform an index scan, Oracle searches the index for the indexed column values accessed by the statement. If the statement accesses only columns of the index, Oracle reads the indexed column values directly from the index, rather than from the table.
In addition to each indexed value, an index also contains the ROWIDs of rows in the table having that value. If the statement accesses other columns in addition to the indexed columns, Oracle then finds the rows in the table with a table access by ROWID or a cluster scan.
An index scan can be one of these types:
Single Row by ROWID This access path is only available if the statement's WHERE clause identifies the selected rows by ROWID or with the CURRENT OF CURSOR embedded SQL syntax supported by the Oracle Precompilers. To execute the statement, Oracle accesses the table by ROWID.
Example
This access path is available in the following statement:
SELECT * FROM emp WHERE ROWID = '00000DC5.0000.0001';
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT TABLE ACCESS BY ROWID EMP
Single Row by Cluster Join This access path is available for statements that join tables stored in the same cluster if both of these conditions are true:
.Example
This access path is available for the following statement in which the EMP and DEPT tables are clustered on the DEPTNO column and the EMPNO column is the primary key of the EMP table:
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno
AND emp.empno = 7900;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
NESTED LOOPS
TABLE ACCESS BY ROWID EMP
INDEX UNIQUE SCAN PK_EMP
TABLE ACCESS CLUSTER DEPT
PK_EMP is the name of an index that enforces the primary key.
Single Row by Hash Cluster Key with Unique or Primary Key This access path is available if both of these conditions are true:
Example
This access path is available in the following statement in which the ORDERS and LINE_ITEMS tables are stored in a hash cluster, and the ORDERNO column is both the cluster key and the primary key of the ORDERS table:
SELECT *
FROM orders WHERE orderno = 65118968;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS HASH ORDERS
Single Row by Unique or Primary Key This access path is available if the statement's WHERE clause uses all columns of a unique or primary key in equality conditions. For composite keys, the equality conditions must be combined with AND operators. To execute the statement, Oracle performs a unique scan on the index on the unique or primary key to retrieve a single ROWID and then accesses the table by that ROWID.
Example
This access path is available in the following statement in which the EMPNO column is the primary key of the EMP table:
SELECT *
FROM emp
WHERE empno = 7900;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
INDEX UNIQUE SCAN PK_EMP
PK_EMP is the name of the index that enforces the primary key.
Clustered Join This access path is available for statements that join tables stored in the same cluster if the statement's WHERE clause contains conditions that equate each column of the cluster key in one table with the corresponding column in the other table. For a composite cluster key, the equality conditions must be combined with AND operators. To execute the statement, Oracle performs a nested loops operation. For information on nested loops operations, see the section "Join Operations" .
Example
This access path is available in the following statement in which the EMP and DEPT tables are clustered on the DEPTNO column:
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
NESTED LOOPS
TABLE ACCESS FULL DEPT TABLE ACCESS CLUSTER EMP
Hash Cluster Key This access path is available if the statement's WHERE clause uses all the columns of a hash cluster key in equality conditions. For a composite cluster key, the equality conditions must be combined with AND operators. To execute the statement, Oracle applies the cluster's hash function to the hash cluster key value specified in the statement to obtain a hash value. Oracle then uses this hash value to perform a hash scan on the table.
Example
This access path is available for the following statement in which the ORDERS and LINE_ITEMS tables are stored in a hash cluster and the ORDERNO column is the cluster key:
SELECT *
FROM line_items
WHERE deptno = 65118968;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS HASH LINE_ITEMS
Indexed Cluster Key This access path is available if the statement's WHERE clause uses all the columns of an indexed cluster key in equality conditions. For a composite cluster key, the equality conditions must be combined with AND operators. To execute the statement, Oracle performs a unique scan on the cluster index to retrieve the ROWID of one row with the specified cluster key value. Oracle then uses that ROWID to access the table with a cluster scan. Since all rows with the same cluster key value are stored together, the cluster scan requires only a single ROWID to find them all.
Example
This access path is available in the following statement in which the EMP table is stored in an indexed cluster and the DEPTNO column is the cluster key:
SELECT * FROM emp WHERE deptno = 10;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS CLUSTER EMP
INDEX UNIQUE SCAN PERS_INDEX
PERS_INDEX is the name of the cluster index.
Composite Index This access path is available if the statement's WHERE clause uses all columns of a composite index in equality conditions combined with AND operators. To execute the statement, Oracle performs a range scan on the index to retrieve the ROWIDs of the selected rows and then accesses the table by those ROWIDs.
Example
This access path is available in the following statement in which there is a composite index on the JOB and DEPTNO columns:
SELECT *
FROM emp
WHERE job = 'CLERK'
AND deptno = 30;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
INDEX RANGE SCAN JOB_DEPTNO_INDEX
JOB_DEPTNO_INDEX is the name of the composite index on the JOB and DEPTNO columns.
Single-Column Indexes This access path is available if the statement's WHERE clause uses the columns of one or more single-column indexes in equality conditions. For multiple single-column indexes, the conditions must be combined with AND operators.
If the WHERE clause uses the column of only one index, Oracle executes the statement by performing a range scan on the index to retrieve the ROWIDs of the selected rows and then accessing the table by these ROWIDs.
Example
This access path is available in the following statement in which there is an index on the JOB column of the EMP table:
SELECT *
FROM emp
WHERE job = 'ANALYST';
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP INDEX RANGE SCAN JOB_INDEX
JOB_INDEX is the index on EMP.JOB.
If the WHERE clauses uses columns of many single-column indexes, Oracle executes the statement by performing a range scan on each index to retrieve the ROWIDs of the rows that satisfy each condition. Oracle then merges the sets of ROWIDs to obtain a set of ROWIDs of rows that satisfy all conditions. Oracle then accesses the table using these ROWIDs.
Oracle can merge up to five indexes. If the WHERE clause uses columns of more than five single-column indexes, Oracle merges five of them, accesses the table by ROWID, and then tests the resulting rows to determine whether they satisfy the remaining conditions before returning them.
Example
This access path is available in the following statement in which there are indexes on both the JOB and DEPTNO columns of the EMP table:
SELECT *
FROM emp
WHERE job = 'ANALYST' AND deptno = 20;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
AND-EQUAL
INDEX RANGE SCAN JOB_INDEX
INDEX RANGE SCAN DEPTNO_INDEX
The AND-EQUAL operation merges the ROWIDs obtained by the scans of the JOB_INDEX and the DEPTNO_INDEX, resulting in a set of ROWIDs of rows that satisfy the query.
Bounded Range Search on Indexed Columns This access path is available if the statement's WHERE clause contains a condition that uses either the column of a single-column index or one or more columns that make up a leading portion of a composite index:
column = expr
column >[=] expr AND column <[=] expr
column BETWEEN expr AND expr
column LIKE 'c%'
Each of these conditions specifies a bounded range of indexed values that are accessed by the statement. The range is said to be bounded because the conditions specify both its least value and its greatest value. To execute such a statement, Oracle performs a range scan on the index and then accesses the table by ROWID.
This access path is not available if expr references the indexed column.
Example
This access path is available in this statement in which there is an index on the SAL column of the EMP table:
SELECT *
FROM emp
WHERE sal BETWEEN 2000 AND 3000;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP INDEX RANGE SCAN SAL_INDEX
SAL_INDEX is the name of the index on EMP.SAL.
Example
This access path is also available in the following statement in which there is an index on the ENAME column of the EMP table:
SELECT *
FROM emp
WHERE ename LIKE 'S%';
Path 11
Unbounded Range Search on Indexed Columns This access path is available if the statement's WHERE clause contains one of these conditions that use either the column of a single-column index or one or more columns of a leading portion of a composite index:
WHERE column >[=] expr
WHERE column <[=] expr
Each of these conditions specify an unbounded range of index values accessed by the statement. The range is said to be unbounded because the condition specifies either its least value or its greatest value, but not both. To execute such a statement, Oracle performs a range scan on the index and then accesses the table by ROWID.
Example
This access path is available in the following statement in which there is an index on the SAL column of the EMP table:
SELECT *
FROM emp WHERE sal > 2000;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP INDEX RANGE SCAN SAL_INDEX
Example
This access path is available in the following statement in which there is a composite index on the ORDER and LINE columns of the LINE_ITEMS table:
SELECT *
FROM line_items
WHERE order > 65118968;
The access path is available because the WHERE clause uses the ORDER column, a leading portion of the index.
Example
This access path is not available in the following statement in which there is an index on the ORDER and LINE columns:
SELECT *
FROM line_items
WHERE line < 4;
The access path is not available because the WHERE clause only uses the LINE column, which is not a leading portion of the index.
Sort-Merge Join This access path is available for statements that join tables that are not stored together in a cluster if the statement's WHERE clause uses columns from each table in equality conditions. To execute such a statement, Oracle uses a sort-merge operation. Oracle can also use a nested loops operation to execute a join statement. For information on these operations and on when the optimizer chooses one over the other, see the section "Optimizing Join Statements" .
Example
This access path is available for the following statement in which the EMP and DEPT tables are not stored in the same cluster:
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
MERGE JOIN
SORT JOIN
TABLE ACCESS FULL EMP
SORT JOIN TABLE ACCESS FULL DEPT
MAX or MIN of Indexed Column This access path is available for a SELECT statement for which all of these conditions are true:
Example
This access path is available for the following statement in which there is an index on the SAL column of the EMP table:
SELECT MAX(sal) FROM emp;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
AGGREGATE GROUP BY
INDEX RANGE SCAN SAL_INDEX
ORDER BY on Indexed Column This access path is available for a SELECT statement for which all of these conditions are true:
Example
This access path is available for the following statement in which there is a primary key on the EMPNO column of the EMP table:
SELECT *
FROM emp
ORDER BY empno;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT
TABLE ACCESS BY ROWID EMP
INDEX RANGE SCAN PK_EMP
PK_EMP is the name of the index that enforces the primary key. The primary key ensures that the column does not contain nulls.
Full Table Scan This access path is available for any SQL statement, regardless of its WHERE clause conditions.
This statement uses a full table scan to access the EMP table:
SELECT * FROM emp;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME
-----------------------------------------------------
SELECT STATEMENT TABLE ACCESS FULL EMP
Note that these conditions do not make index access paths available:
The order of the conditions in the WHERE clause does not normally affect the optimizer's choice among access paths.
Example
Consider this SQL statement, which selects the employee numbers of all employees in the EMP table with an ENAME value of 'CHUNG' and with a SAL value greater than 2000:
SELECT empno
FROM emp
WHERE ename = 'CHUNG'
AND sal > 2000;
Consider also that the EMP table has these integrity constraints and indexes:
Using the rule-based approach, the optimizer chooses the access path that uses the ENAME_IND index to execute this statement. The optimizer chooses this path because it is the most highly ranked path available.
Choosing Among Access Paths with the Cost-Based Approach With the cost-based approach, the optimizer chooses an access path based on these factors:
The optimizer's choice among available access paths can be overridden with hints. For information on hints, see Chapter 7, "Tuning SQL Statements".
To choose among available access paths, the optimizer considers these factors:
SELECT *
FROM emp WHERE ename = 'JACKSON';
If the ENAME column is a unique or primary key, the optimizer determines that there is only one employee named Jackson, and the query returns only one row. In this case, the query is very selective, and the optimizer is most likely to access the table using a unique scan on the index that enforces the unique or primary key (access path 4).
Example
Consider again the query in the previous example. If the ENAME column is not a unique or primary key, the optimizer can use these statistics to estimate the query's selectivity:
| USER_TAB_COLUMNS. NUM_DISTINCT | This statistic is the number of values for each column in the table. |
| USER_TABLES.NUM_ROWS | This statistic is the number of rows in each table. |
Example
Consider this query, which selects all employees with employee ID numbers less than 7500:
SELECT *
FROM emp
WHERE empno < 7500;
To estimate the selectivity of the query, the optimizer uses the boundary value of 7500 in the WHERE clause condition and the values of the HIGH_VALUE and LOW_VALUE statistics for the EMPNO column if available. These statistics can be found in the USER_TAB_COLUMNS view. The optimizer assumes that EMPNO values are evenly distributed in the range between the lowest value and highest value. The optimizer then determines what percentage of this range is less than the value 7500 and uses this value as the estimated selectivity of the query.
Example
SELECT *
FROM emp
WHERE empno < :e1;
The optimizer does not know the value of the bind variable E1. Indeed, the value of E1 may be different for each execution of the query. For this reason, the optimizer cannot use the means described in the previous example to determine selectivity of this query. In this case, the optimizer heuristically guesses a small value for the selectivity of the column (because it is indexed). The optimizer makes this assumption whenever a bind variable is used as a boundary value in a condition with one of the operators <, >, <=, or >=.
The optimizer's treatment of bind variables can cause it to choose different execution plans for SQL statements that differ only in the use of bind variables rather than constants. In one case in which this difference may be especially apparent, the optimizer may choose different execution plans for an embedded SQL statement with a bind variable in an Oracle Precompiler program and the same SQL statement with a constant in SQL*Plus.
Example
Consider this query, which uses two bind variables as boundary values in the condition with the BETWEEN operator:
SELECT *
FROM emp
WHERE empno BETWEEN :low_e AND :high_e;
The optimizer decomposes the BETWEEN condition into these two conditions:
empno >= :low_e
empno <= :high_e
The optimizer heuristically estimates a small selectiviy for indexed columns in order to favor the use of the index.
Example
Consider this query, which uses the BETWEEN operator to select all employees with employee ID numbers between 7500 and 7800:
SELECT *
FROM emp
WHERE empno BETWEEN 7500 AND 7800;
To determine the selectivity of this query, the optimizer decomposes the WHERE clause condition into these two conditions:
empno >= 7500
empno <= 7800
The optimizer estimates the individual selectivity of each condition using the means described in a previous example. The optimizer then uses these selectivities (S1 and S2) and the absolute value function (ABS) in this formula to estimate the selectivity (S) of the BETWEEN condition:
S = ABS( S1 + S2 - 1 )
| access paths | As for simple statements, the optimizer must choose an access path to retrieve data from each table in the join statement. |
| join operations | To join each pair of row sources, Oracle must perform one of these operations: |
| join order | To execute a statement that joins more than two tables, Oracle joins two of the tables, and then joins the resulting row source to the next table. This process is continued until all tables are joined into the result. |
SELECT *
FROM emp, dept
WHERE emp.deptno = dept.deptno;
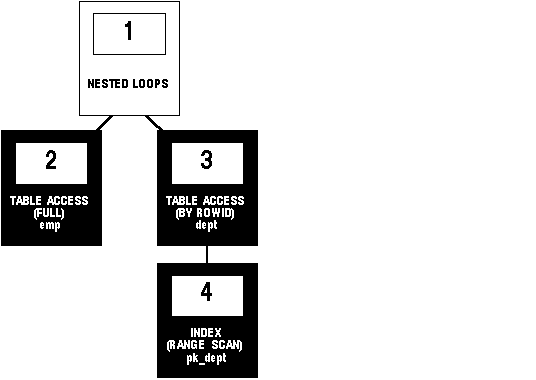 Figure 5 - 7. Nested Loops Join
Figure 5 - 7. Nested Loops Join
To execute this statement, Oracle performs these steps:
Figure 5 - 8 shows the execution plan for this statement using a sort-merge join:
SELECT *
FROM emp, dept WHERE emp.deptno = dept.deptno;
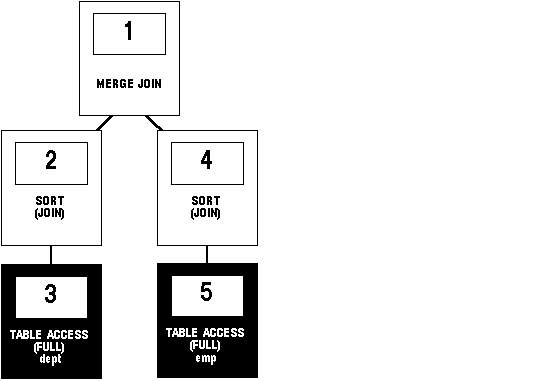 Figure 5 - 8. Sort-Merge Join
Figure 5 - 8. Sort-Merge Join
To execute this statement, Oracle performs these steps:
Figure 5 - 9 shows the execution plan for this statement in which the EMP and DEPT tables are stored together in the same cluster:
SELECT *
FROM emp, dept WHERE emp.deptno = dept.deptno;
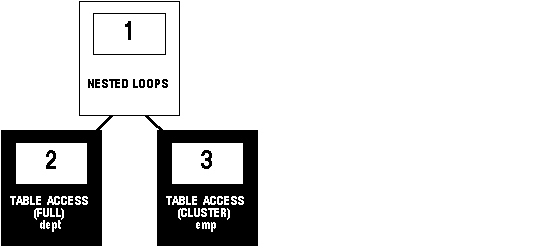 Figure 5 - 9. Cluster Join
Figure 5 - 9. Cluster Join
To execute this statement, Oracle performs these steps:
Figure 5 - 10 shows the execution plan for this statement, which uses the UNION ALL operator to select all occurrences of all parts in either the ORDERS1 table or the ORDERS2 table:
SELECT part FROM orders1
UNION ALL
SELECT part FROM orders2;
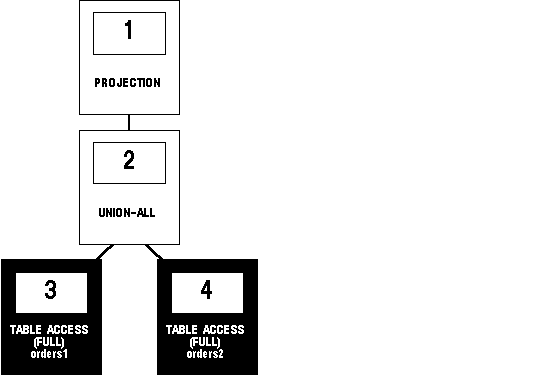 Figure 5 - 10. Compound Query with UNION ALL Set Operator
Figure 5 - 10. Compound Query with UNION ALL Set Operator
To execute this statement, Oracle performs these steps:
SELECT part FROM orders1
UNION
SELECT part FROM orders2;
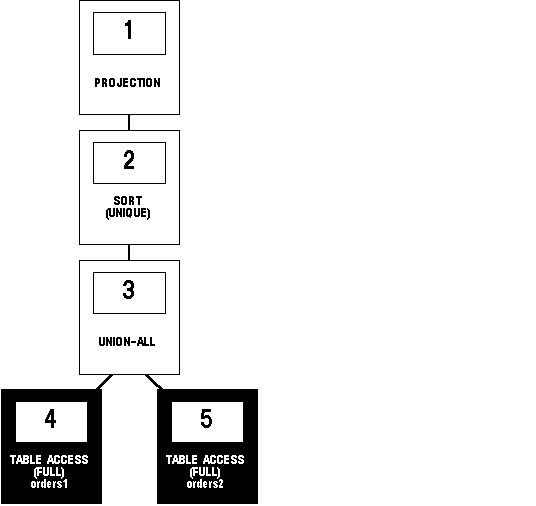 Figure 5 - 11. Compound Query with UNION Set Operator
Figure 5 - 11. Compound Query with UNION Set Operator
This execution plan is identical to the one for the UNION-ALL operator shown in Figure 5 - 10, except that in this case Oracle uses the SORT operation to eliminate the duplicates returned by the UNION-ALL operation.
Figure 5 - 12 shows the execution plan for this statement, which uses the INTERSECT operator to select only those parts that appear in both the ORDERS1 and ORDERS2 tables:
SELECT part FROM orders1
INTERSECT
SELECT part FROM orders2;
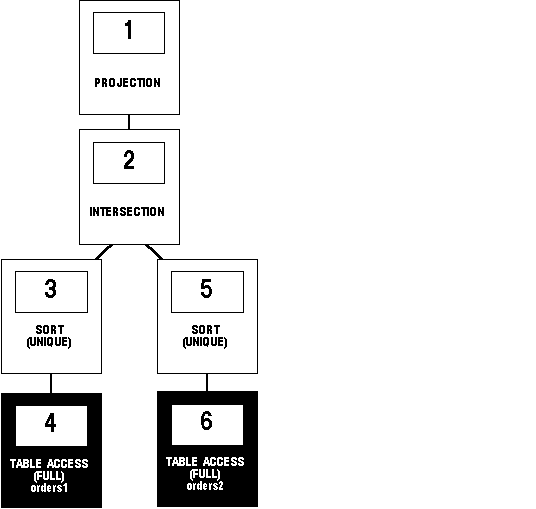 Figure 5 - 12. Compound Query with INTERSECT Set Operator
Figure 5 - 12. Compound Query with INTERSECT Set Operator
To execute this statement, Oracle performs these steps: