





SQL*Loader inserts as many rows as are specified by the LOAD keyword. The LOAD keyword is required in this situation. The SKIP keyword is not permitted.
SQL*Loader is optimized for this case. Whenever SQL*Loader detects that only generated specifications are used, it ignores any specified datafile -- no read I/O is performed.
In addition, no memory is required for a bind array. If there are any WHEN clauses in the control file, SQL*Loader assumes that data evaluation is necessary, and input records are read.
CONSTANT value
CONSTANT data is interpreted by SQL*Loader as character input. It is converted, as necessary, to the database column type.
You may enclose the value within quotation marks, and must do so if it contains white space or reserved words. Be sure to specify a legal value for the target column. If the value is bad, every row is rejected.
Numeric values larger than 2**32 - 1 (4,294,967,295) must be enclosed in quotes.
Note: Do not use the CONSTANT keyword to set a column to null. To set a column to null, do not specify that column at all. Oracle automatically sets that column to null when loading the row. The combination of CONSTANT and a value is a complete column specification.
column_name RECNUM
column_name SYSDATE
The database column must be of type CHAR or DATE. If the column is of type CHAR, then the date is loaded in the form 'dd-mon-yy.' After the load, it can be accessed only in that form. If the system date is loaded into a DATE column, then it can be accessed in a variety of forms that include the time and the date.
A new system date/time is used for each array of records inserted in a conventional path load and for each block of records loaded during a direct path load.
SEQUENCE takes two optional arguments. The first argument is the starting value. The second is the increment. If the start point is a positive integer n, the first row inserted has a value of n for that column. The values of successive rows are increased by the increment. However, both the starting value and the increment default to 1.
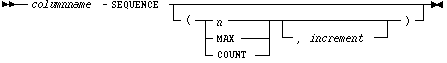
where:
| SEQUENCE | Use the SEQUENCE keyword to specify the value for a column. |
| n | The sequence starts with the integer value n. The value must be positive or zero. Default value is 1. |
| COUNT | The sequence starts with the number of rows already in the table, plus the increment. |
| MAX | The sequence starts with the current maximum value for the column, plus the increment. |
| increment | The sequence is incremented by this amount for each successive row. The default increment is 1. The increment must be positive. |
Case 3 ![[*]](jump.gif) provides an example of using SEQUENCE.
provides an example of using SEQUENCE.
illustrates this situation. Sometimes, you might want to generate different sequence numbers for each INTO TABLE clause. For example, your data format might define three logical records in every input record. In that case, you can use three INTO TABLE clauses, each of which inserts a different part of the record into the same table.
To generate sequence numbers for these records, you must generate unique numbers for each of the three inserts. There is a simple technique to do so. Use the number of table-inserts per record as the sequence increment and start the sequence numbers for each insert with successive numbers.
Accounting Personnel Manufacturing
Shipping Purchasing Maintenance
...
You could use the following control file to generate unique department numbers:
INTO TABLE dept
(deptno sequence(1, 3),
dname position(1:14) char)
INTO TABLE dept
(deptno sequence(2, 3),
dname position(16:29) char)
INTO TABLE dept
(deptno sequence(3, 3),
dname position(31:44) char)
The first INTO TABLE clause generates department number 1, the second number 2, and the third number 3. They all use 3 as the sequence increment (the number of department names in each record). This control file loads Accounting as department number 1, Personnel as 2, and Manufacturing as 3. The sequence numbers are then incremented for the next record, so Shipping loads as 4, Purchasing as 5, and so on.