The following figure illustrates the left-most columns of the System Statistics Monitor.
| User Statistic
| Description
|
| CPU used by this session
| Amount of CPU time used in 1/100's of a second.
|
| logons cumulative
| On a systemwide basis, the number in the CURRENT column is the number of new logons this cycle and always equals the corresponding number in current logons. On a per-process basis, this number is always 0 or 1. The number in the TOTAL column is the number of processes that have ever logged on and is cumulative from the last warm start.
|
| opened cursors cumulative
| The total number of cursors that have been opened.
|
| logons current
| The number of current logons.
|
| opened cursors current
| The number of cursors that are currently open.
|
| cursor authentications
| The number of times that cursor privileges have been verified, either for a SELECT or because privileges were revoked from an object, causing all users of the cursor to be re-authenticated.
|
| session logical reads
| The number of logical disk reads that were satisfied either from the cache or by a physical read from the disk.
|
| session pga memory max
| Maximum amount of PGA memory ever used.
|
| session uga memory max
| Maximum amount of system memory ever used.
|
| session pga memory
| Amount of PGA memory currently in use.
|
| recursive calls
| The number of recursive calls including data dictionary operations. A high number indicates that information is not being found often enough in the dictionary cache. This could be because parsing is occurring (too) often or because the cache is not large enough. You should consider increasing the initialization parameter SHARED_POOL_SIZE.
|
| recursive cpu usage
| The amount of CPU time (in 1/100's of a second) that was spent updating internal tables while processing user SQL statements; for example, time spent doing space allocation. A high value indicates a lot of data dictionary work.
|
| session connect time
| The total elapsed time that the session has been connected to the server, in 1/100's of a second.
|
| session uga memory
| Amount of used session memory.
|
| session stored procedure space
| The number of bytes allocated to stored procedures used in the session.
|
| user calls
| The number of user calls processed.
|
| user commits
| The number of transactions for this process or systemwide. This number should equal USER CALLS minus USER ROLLBACKS.
|
| user rollbacks
| The number of rollbacks for this process.
|
| Redo Statistic
| Description
|
| redo blocks written
| The total number of redo blocks written.
|
| redo buffer allocation retries
| The total number of retries necessary to allocate space in the redo buffer. Retries are needed either because the redo writer has fallen behind or because an event such as a log switch is occurring.
|
| redo entries
| The number of redo entries generated.
|
| redo entries linearized
| The number of entries less than or equal to REDO_ENTRY_PREBUILD_THRESHOLD. Building these entries requires additional CPU time but increases concurrency on multiple-user systems.
|
| redo log space requests
| Number of times LGWR was given a request to write a redo log buffer.
|
| redo log space wait time
| Time spent waiting for log space (in 1/100's of a second). A very high or rapidly increasing value may indicated a problem with log archiving.
|
| redo log switch interrupts
| The count of times an instance log-switch was requested by another instance when running in parallel mode.
|
| redo ordering marks
| Number of extra SCN's allocated to maintain ordering of redo logs, as a result of blocks migrating from one instance's cache to another. The count of these pings is a measurement of cross-talk between instances when running in parallel mode. If this value is very high, it may indicate a need for a better separation of instance-activities.
|
| redo size
| The amount of redo generated in bytes.
|
| redo small copies
| The total number of entries less than or equal to LOG_SMALL_ENTRY_MAX_SIZE. These entries are copied under the protection of the allocation latch, eliminating the necessity of the copy latch. This statistic generally is applicable to only multiple-processor systems.
|
| redo wastage
| Cumulative total of unused bytes that were written to the log. The redo buffer is flushed periodically even when not completely filled, so this value may be nonzero.
|
| redo write time
| Cumulative elapsed time spent on log I/O.
|
| redo writes
| The total number of redo writes.
|
| Cache Statistic
| Description
|
| background checkpoints completed
| The number of times DBWR completes a checkpoint.
|
| background checkpoints started
| The number of times DBWR starts a checkpoint.
|
| buffer busy waits
| The number of times that a user process wanted a buffer in a mode that is incompatible with the current use of that buffer. A high value indicates block level contention.
|
| busy wait time
| Amount of time spent in buffer busy waits in 1/100's of a second.
|
| change write time
| Amount of time spent waiting for redo buffer space, inserting redo information into the buffer, and allocating an SCN, if needed, in 1/100's of a second.
|
| consistent changes
| The number of log changes to produce read-consistent blocks.
|
| consistent gets
| The number of logical reads in read-consistent mode. The sum of this number and db block gets equals logical reads.
|
| cross instance CR read
| The number of times the current instance had to do a consistent read in parallel mode. These tend to be slow, since every instance is told to write out the block. Instance functions should be arranged so that this value is kept small.
|
| db block changes
| The number of logical changes to current database blocks.
|
| db block gets
| The number of requests for the current copy of a block. This number plus consistent gets equals logical reads.
|
| DBWR buffers scanned
| The number of buffers in the lru scanned by DBWR when looking for dirty buffers to flush to disk. This count includes both dirty and clean buffers. Divide by "DBWR lru scans" to get the average number of buffers scanned.
|
| DBWR checkpoints
| The number of times DBWR was notified to do a checkpoint.
|
| DBWR cross instance writes
| The number of blocks written for cross-instance calls so that another instance could do a consistent read.
|
| DBWR exchange waits
| Used in the Parallel Server only, the number of times the DBWR was requested to exchange blocks between instances. Useful only when shown for the DBWR process.
|
| DBWR free buffers found
| The number of buffers that DBWR found already clean when requested to make free buffers. Divide by "DBWR make free requests" to find the average number of reusable buffers at the end of the lru. This value is only incremented when the lru is scanned in response to a make-free request.
|
| DBWR lru scans
| The number of times DBWR does a scan of the lru queue looking for more buffers to write. This includes times when the scan is made to fill out a batch being written for another purpose, such as a checkpoint, so it will always be equal to or greater than "DBWR make free requests".
|
| DBWR make free requests
| The number of requests received by DBWR to make more free buffers for the lru. This includes the times that DBWR sends such a request to itself.
|
| DBWR summed scan depth
| Sum of the current scan depth for each scan of the lru by DBWR when DBWR is looking for dirty buffers. The actual number of buffers scanned may be less than the scan depth, as a result of dirty buffers being placed in the dirty queue by foreground processes. Divide by "DBWR lru scans" to find the average scan depth. Compare this value with the value calculated from "DBWR buffers scanned" to see how much scanning is actually performed.
|
| DBWR timeouts
| The number of timeouts at which DBWR had been idle since the last timeout. These are the times that DBWR looked for buffers to idle write.
|
| dirty buffers inspected
| Number of modified buffers found in the cache. If this value is very large or increasing rapidly, then DBWR is not working fast enough. Tuning may be required.
|
| exchange deadlocks
| The number of times that a process detected a potential deadlock when exchanging two buffers and so raised an internal, restartable error. Index operations are the only operations that perform exchanges. If this number is high, increase the parameters GC_DB_LOCKS and DB_BLOCK_BUFFERS.
|
| free buffer inspected
| The number of buffers skipped in the buffer cache to find a free buffer. High values potentially indicate that user processes are doing too much work and DBWR not enough.
|
| free buffer requested
| The total number of free buffers needed.
|
| free buffer waits
| The number of times a process needed a free buffer (to read from the disk or to make a read-consistent block) and a free buffer was not available.
|
| free wait time
| Time spent waiting for a free buffer, in 1/100's of a second. If this value is very large, or rapidly increasing, then DBWR is not keeping pace with database activity, and tuning may be indicated.
|
| hash latch wait gets
| The number of times latches had to be obtained using waits rather no-wait gets. If this value is large, or rapidly increasing, you can increase the number of hash latches.
|
| lock element waits
| The number of waits for a parallel cache lock.
|
| physical reads
| The number of actual reads of database blocks from disk.
|
| physical writes
| The number of actual writes to disk made by DBWR. For multiple-user systems, this value is always 0, except for DBWR.
|
| redo synch time
| The amount of time waiting for redo logs to be written after a COMMIT in 1/100's of a second.
|
| redo synch writes
| The number of times the redo is forced to disk, usually for transaction commit.
|
| remote instance undo requests
| The number of times this instance acquired an SS lock on undo from another instance in order to perform a consistent read.
|
| remote instance undo writes
| The number of times this instance wrote a dirty undo block so another instance could read it.
|
| summed dirty queue length
| The number of buffers pending for writing. If this value is large, or increasing rapidly, then increase the write-batch size.
|
| write complete waits
| The number of times a process waited for DBWR to write a current block before making a change.
|
| write requests
| The number of multi-block writes performed.
|
| write wait time
| The amount of time spent waiting for DBWR to finish writing a block in the buffer cache before being allowed to change it.
|
| Parallel Server Statistic
| Description
|
| cross instance CR read
| The number of times the current instance had to do a consistent read in parallel mode. These tend to be slow, since every instance is told to write out the block. Instance functions should be arranged so that this value is kept small.
|
| DBWR cross instance writes
| The number of blocks written for cross-instance calls so that another instance could do a consistent read.
|
| global lock converts (asynchronous)
| The number of instance locks that were converted from one mode to another, during which other tasks were enabled.
|
| global lock converts (non-asynchronous)
| The number of instance locks that were converted from one mode to another, during which no other tasks could run.
|
| global lock converts time
| The amount of time spent waiting for instance lock conversion in 1/100's of a second.
|
| global lock gets (asynchronous)
| The number of instance locks that were acquired when other tasks could be enabled during the wait.
|
| global lock gets (non-asynchronous)
| The number of instance locks that were acquired when other tasks could run during the wait.
|
| global lock get time
| The amount of time spent waiting to acquire instance locks in 1/100's of a second.
|
| global lock releases (asynchronous)
| The number of instance locks that were released when other tasks could be enabled during the wait.
|
| global lock releases (nonasynchronous)
| The number of instance locks that were released when other tasks could run during the wait.
|
| global lock release time
| The amount of time spent waiting to release instance locks in 1/100's of a second.
|
| hash latch wait gets
| The number of times latches had to be obtained using waits rather than no-wait gets. If this value is large, or rapidly increasing, you can increase the number of hash latches.
|
| lock element waits
| The number of waits for a parallel cache lock
|
| next SCNs gotten without going to DLM
| The number of SCNs obtained without resorting to Distributed Lock management. To measure the effectiveness of the Parallel Server's SCN cache, divide this value by the total number of SCN gets as given by the user statistic "user commits". This gives the percentage of SCN gets satisfied from the cache.
|
| remote instance undo requests
| The number of times this instance acquired an SS lock on undo from another instance in order to perform a consistent read.
|
| remote instance undo writes
| The number of times this instance wrote a dirty undo block so another instance could read it.
|
| SQL Tuning Statistic
| Description
|
| cluster key scans
| The number of full table scans or clustered tables performed by fetching rows using the cluster key.
|
| cluster key scan block gets
| The number of blocks read while performing full table scans or clustered tables using the cluster key.
|
| table fetch by rowid
| The number of logical rows fetched from a table.
|
| table fetch continued row
| The number of additional physical fetches required to access broken rows. Divide this number by "table fetch by rowid" for a percentage of broken rows, where rows with multiple breaks count as multiple broken rows.
|
| table scan rows gotten
| The number of rows fetched during full table scans.
|
| table scan blocks gotten
| Number of logical block reads during table scans.
|
| table scans (long tables)
| The number of long table scans. All blocks in excess of the value specified by the parameter SMALL_TABLE_THRESHOLD are immediately resumed, instead of aging out of the lru queue.
|
| table scans (short tables)
| The number of full table scans of short tables. All of the table's blocks are aged out of the lru queue in normal fashion. These tables are smaller than the value of SMALL_TABLE_THRESHOLD.
|
| parse count
| The number of SQL statements parsed.
|
| parse time cpu
| The amount of CPU time spent parsing SQL statements, in 1/100's of a second.
|
| parse time elapsed
| The amount of elapsed time spent parsing SQL statements, in 1/100's of a second.
|
| sorts (disk)
| The number of disk sorts. Each disk sort requires the memory specified by the SORT_AREA_SIZE parameter.
|
| sorts (rows)
| The number of rows sorted.
|
| sorts (memory)
| The number of in-memory sorts. Sorts remain in memory when the total required sort space is less than the value specified by the SORT_AREA_RETAINED_SIZE parameter.
|






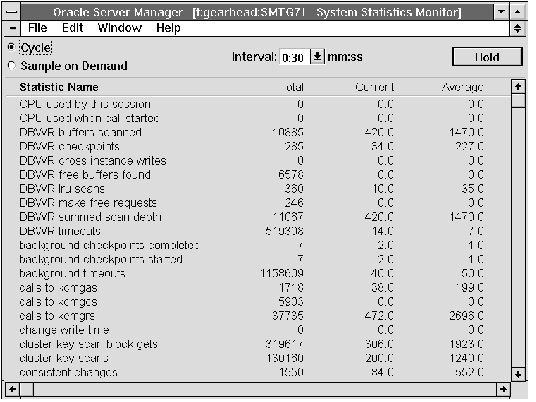 Figure 11 - 14. System Statistics Monitor
Figure 11 - 14. System Statistics Monitor