





A good example of an appropriate application is a purge operation (also referred to as an archive operation) run infrequently (for
example, once per quarter) during off hours to remove old data, or data that was "logically" deleted from the online database. An example using procedural replication to purge deleted rows is described ![[*]](jump.gif) .
.
The symmetric replication facility cannot detect update conflicts produced by replicated procedures. Replicated procedures must detect and resolve conflicts themselves. Because of the difficulties involved in writing your own conflict resolution routines, it is best to simply avoid the possibility of conflicts.
Adhering to the following guidelines will help you ensure that your tables remain consistent at all sites.
.
.When you generate replication support for your replicated package, the symmetric replication facility creates a wrapper package. The wrapper package has the same name as the original, but is prefixed with the string that you supplied when you called DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT.
If you did not supply a prefix, the default, "defer_", is used. The wrapper procedure has the same parameters as the original, along with two additional parameters: CALL_LOCAL and CALL_REMOTE. These two boolean parameters determine where the procedure gets executed. When CALL_LOCAL is TRUE, the procedure is executed locally. When CALL_REMOTE is TRUE, the procedure will ultimately be executed at all other sites in the replicated environment.
The remote procedures are called directly if you are propagating changes synchronously, or the calls to these procedures are added to the deferred transaction queue, if you are propagating changes asynchronously. By default, CALL_LOCAL is FALSE, and CALL_REMOTE is TRUE.
Replication support is generated in two phases. The first phase creates the package specification at all sites. Phase two generates the package body at all sites. These two phases are necessary to support synchronous replication.
For example, suppose that you create the package UPDATE containing the procedure UPDATE_EMP, which takes one argument, AMOUNT. You replicate this object to all master sites in your replicated environment by making the following calls:
DBMS_REPCAT.CREATE_MASTER_REPOBJECT(
sname => 'acct_rec',
oname => 'update',
type => 'package',
use_existing_object => FALSE,
retry => FALSE,
copy_rows => TRUE,
gname => 'acct');
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT(
sname => 'acct_rec',
oname => 'update',
type => 'package',
package_prefix => 'defer_',);You would now invoke the replicated procedure as shown below:
defer_update.update_emp( amount => 1.05,
call_local => TRUE,
call_remote => TRUE);As shown in Figure 8 - 3, the logic of the wrapper procedure ensures that the procedure is called at the local site and then at all remote sites. The logic of the wrapper procedure also ensures that when the replicated procedure is called at the remote sites, CALL_REMOTE is FALSE, ensuring that the procedure is not further propagated.
If you are operating in a mixed replicated environment with static partitioning of data ownership (that is, if you are not preventing row-level replication), the replication facility will preserve the order of operations at the remote node, since both row-level and procedural replication use the same asynchronous queue.

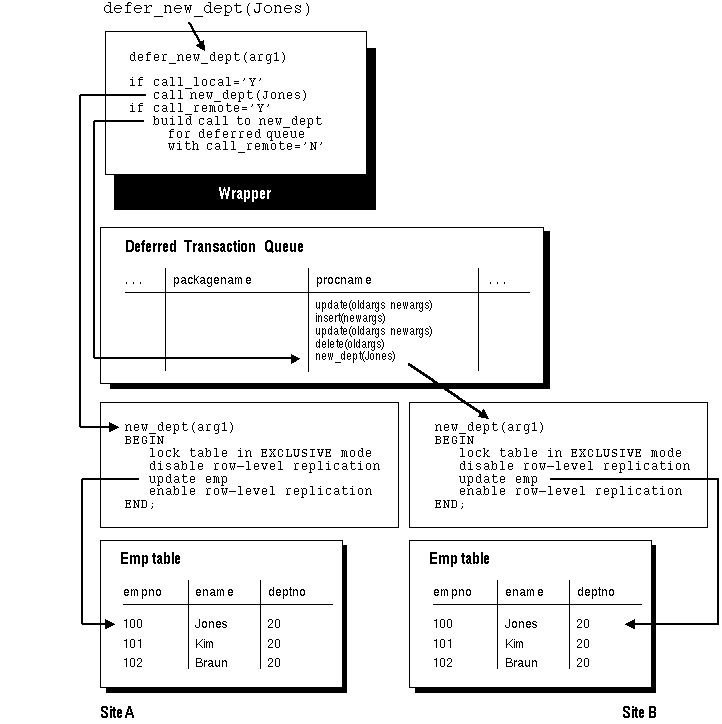 Figure 8 - 3. Asynchronous Procedural Replication
Figure 8 - 3. Asynchronous Procedural Replication