With primary site replication, each piece of information is owned by one site, and this ownership never changes. Other sites "subscribe" to the data owned by the primary site, which means that they have access to read-only copies of the replicated data. With primary site replication, you never need to worry about any discrepancies between data that is being updated at two different locations.
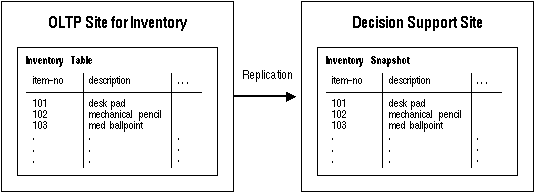 Figure 2 - 1. Information Offloading
Figure 2 - 1. Information Offloading
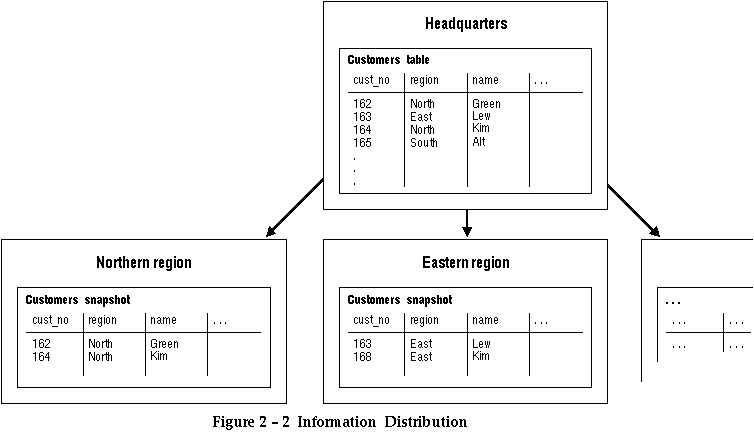
Portions of this information might be used by your sales offices around the world. Instead of replicating the entire table at each sales office, you need only replicate the portions appropriate for that region, as shown in Figure 2 - 2.
For performance reasons, however, you might want to allow local updates of the data, thus allowing multiple sites to have access to a single table. You can still successfully avoid conflicts by implementing an advanced form of primary site ownership.
Instead of designating one site as the owner of the entire table, each site is allowed to "own" a distinct portion of this table. That is, each site would be allowed to modify only a subset of the rows or columns in each table. You might think of this as allowing each site to own a distinct horizontal or vertical partition of the data in a single table.
Ownership can either be enforced by your application, or can be enforced by using a combination of triggers, views, procedures, and horizontally partitioned updatable snapshots.
The CREATE statement for a snapshot of your CUSTOMERS table might look like
CREATE SNAPSHOT customers FOR UPDATE AS SELECT * FROM customers@hq.com WHERE region = 'North East';
Note: Ownership of vertical partitions requires the use of column groups. Column groups are described ![[*]](jump.gif) .
.
Each application module acts on an order, that is, performs updates to the order data, when the state of the order indicates that the previous processing steps have been completed. For example, the application module that ships an order will do so only after the order has been entered and approved.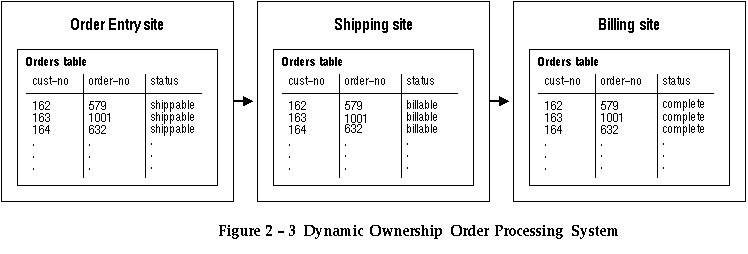
By employing a dynamic ownership replication technique, such a system can be distributed across multiple sites and databases. Application modules can reside on different systems. For example, order entry and approval can be performed on one system, shipping on another, billing on another, and so on. Order data is replicated to a site when its state indicates that it is ready for the processing step performed by that site. Data may also be replicated to sites that need read-only access to the data. For example, order entry sites may wish to monitor the progression of processing steps for the orders they enter.
In some situations, however, it is desirable to allow multiple sites to update the same data, potentially at the same time. For example, it may be desirable to replicate customer data across multiple sites and systems rather than maintaining customer data centrally or maintaining it separately and redundantly within each system. Different sites, though, may need to update this data.
This occurrence is known as an update conflict. Replicated data has become inconsistent because the replicated data was updated at multiple sites. If you cannot tolerate such inconsistencies, you must either carefully partition ownership of your data or only allow for synchronous propagation of changes between sites. If all sites in your replicated environment are propagating changes to one another synchronously, update conflicts cannot occur. If, however, you have even one site sending or receiving changes asynchronously (for example, if you have an updatable snapshot site), you have the potential for conflicts. For some applications, these temporary inconsistencies can be permitted as long as they can be detected and resolved to ensure that over time the replicated data converges to a consistent state at all sites.
The symmetric replication facility provides a number of standard resolution routines from which the application developer can select. Standard resolution routines include: timestamp determined most recent update, commutative resolution of additive updates, applying the change from the site with the highest priority value, and min/max selection of updates. Alternatively, for more specialized cases, the application developer can write his or her own routines.
In the scenario above, a routine that uses timestamps to determine the most recent update can be employed so that the customer's address converges to the most recent update of the address at all sites. Update conflicts on the address will be automatically detected and immediately resolved at each site by selecting the most recent of the updates.
For example, an earlier discussion described how a distributed order entry system could be implemented using primary site replication techniques with horizontal partitioning.
In this scenario each sales office owned a distinct horizontal partition of the tables containing orders and customer information for the customers serviced by that office. Each sales office entered orders for its customers, but no others. 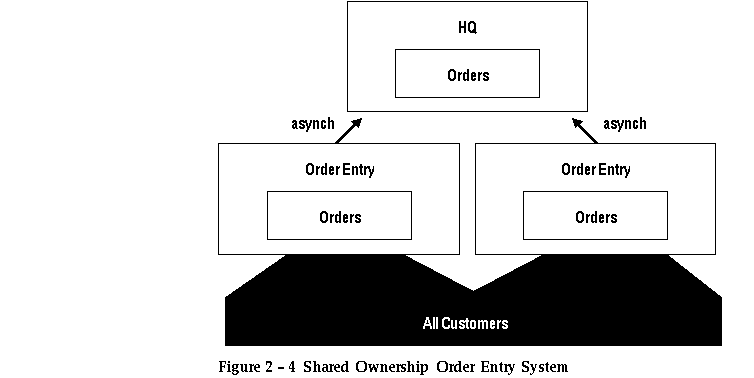
For some businesses, though, this is not the model. For example, a retail chain may have several stores in a metropolitan area. Customers may frequent the store closest to where they live, but they will go into other stores; and these others stores will want to take their orders when they do. If multiple stores perform updates to the same customer and order data, as illustrated in Figure 2 - 4, update conflicts potentially could occur. Sophisticated application developers can identify these conflicts and either select standard resolution routines or devise their own to implement such systems.