





The absence or presence of an index does not require a change in the wording of any SQL statement. An index is merely a fast access path to the data; it affects only the speed of execution. Given a data value that has been indexed, the index points directly to the location of the rows containing that value.
Indexes are logically and physically independent of the data in the associated table. You can create or drop an index at anytime without effecting the base tables or other indexes. If you drop an index, all applications continue to work; however, access of previously indexed data might be slower. Indexes, as independent structures, require storage space.
Oracle automatically maintains and uses indexes once they are created. Oracle automatically reflects changes to data, such as adding new rows, updating rows, or deleting rows, in all relevant indexes with no additional action by users.
Oracle recommends that you do not explicitly define unique indexes on tables; uniqueness is strictly a logical concept and should be associated with the definition of a table. Alternatively, define UNIQUE integrity constraints on the desired columns. Oracle enforces UNIQUE integrity constraints by automatically defining a unique index on the unique key.
Composite indexes can speed retrieval of data for SELECT statements in which the WHERE clause references all or the leading portion of the columns in the composite index. Therefore, you should give some thought to the order of the columns used in the definition; generally, the most commonly accessed or most selective columns go first. For more information on composite indexes, see Oracle7 Server Tuning.
Figure 5 - 6 illustrates the VENDOR_PARTS table that has a composite index on the VENDOR_ID and PART_NO columns.

Figure 5 - 6. Indexes, Primary keys, Unique Keys, and Foreign Keys
No more than 16 columns can form the composite index, and a key value cannot exceed roughly one-half (minus some overhead) the available data space in a data block.
Integrity constraints enforce the business rules of a database; see Chapter 7, "Data Integrity". Because Oracle uses indexes to enforce some integrity constraints, the terms key and index are often are used interchangeably; however, they should not be confused with each other.
![[*]](jump.gif) .
.
Additional Information: See your Oracle operating system-specific documentation for more information about the overhead of an index block.
When you create an index, Oracle fetches and sorts the columns to be indexed, and stores the ROWID along with the index value for each row. Then Oracle loads the index from the bottom up. For example, consider the statement:
CREATE INDEX emp_ename ON emp(ename);
Oracle sorts the EMP table on the ENAME column. It then loads the index with the ENAME and corresponding ROWID values in this sorted order. When it uses the index, Oracle does a quick search through the sorted ENAME values and then uses the associated ROWID values to locate the rows having the sought ENAME value.
Though Oracle accepts the keywords ASC, DESC, COMPRESS, and NOCOMPRESS in the CREATE INDEX command, they have no effect on index data, which is stored using rear compression in the branch nodes but not in the leaf nodes.
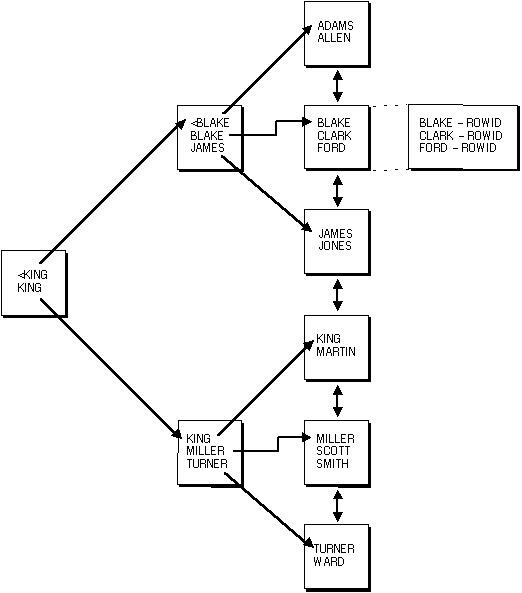
Figure 5 - 7. Internal Structure of a B*-Tree Index
The upper blocks (branch blocks) of a B*-tree index contain index data that points to lower level index blocks. The lowest level index blocks (leaf blocks) contain every indexed data value and a corresponding ROWID used to locate the actual row; the leaf blocks are doubly linked. Indexes in columns containing character data are based on the binary values of the characters in the database character set.
For a unique index, there is one ROWID per data value. For a non-unique index, the ROWID is included in the key in sorted order, so non-unique indexes are sorted by the index key and ROWID. Key values containing all nulls are not indexed, except for cluster indexes. Two rows can both contain all nulls and not violate a unique index.
The B*-tree structure has the following advantages: