Oracle7 Server Concepts






Tables
Tables are the basic unit of data storage in an Oracle database. Data is stored in rows and columns. You define a table with a table name (such as EMP) and set of columns. You give each column a column name (such as EMPNO, ENAME, and JOB), a datatype (such as VARCHAR2, DATE, or NUMBER), and a width (the width might be predetermined by the datatype, as in DATE) or precision and scale (for columns of the NUMBER datatype only). A row is a collection of column information corresponding to a single record.
Note: See Chapter 6, "Datatypes", for a discussion of the Oracle datatypes.
You can optionally specify rules for each column of a table. These rules are called integrity constraints. One example is a NOT NULL integrity constraint. This constraint forces the column to contain a value in every row. See Chapter 7, "Data Integrity", for more information about integrity constraints.
Once you create a table, you insert rows of data using SQL statements. Table data can then be queried, deleted, or updated using SQL.
Figure 5 - 2 shows a table named EMP.
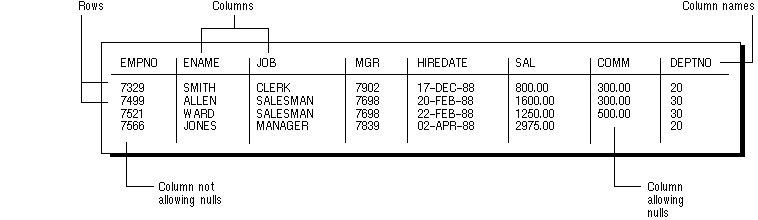
Figure 5 - 2. The EMP Table
How Table Data Is Stored
When you create a non-clustered table, Oracle automatically allocates a data segment in a tablespace to hold the table's future data. You can control the allocation of space for a table's data segment and use of this reserved space in the following ways:
- You can control the use of the free space in the data blocks that constitute the data segment's extents by setting the PCTFREE and PCTUSED parameters for the data segment.
Oracle stores data for a clustered table in the data segment created for the cluster. Storage parameters cannot be specified when a clustered table is created or altered; the storage parameters set for the cluster always control the storage of all tables in the cluster.
The tablespace that contains a non-clustered table's data segment is either the table owner's default tablespace or a tablespace specifically named in the CREATE TABLE statement. See "User Tablespace Settings and Quotas" ![[*]](jump.gif) .
.
Row Format and Size
Oracle stores each row of a database table as one or more row pieces. If an entire row can be inserted into a single data block, Oracle stores the row as one row piece. However, if all of a row's data cannot be inserted into a single data block or an update to an existing row causes the row to outgrow its data block, Oracle stores the row using multiple row pieces. A data block usually contains only one row piece per row. When Oracle must store a row in more than one row piece, it is "chained" across multiple blocks. A chained row's pieces are chained together using the ROWIDs of the pieces. See "Row Chaining across Data Blocks" .
Each row piece, chained or unchained, contains a row header and data for all or some of the row's columns. Individual columns might also span row pieces and, consequently, data blocks. Figure 5 - 3 shows the format of a row piece.
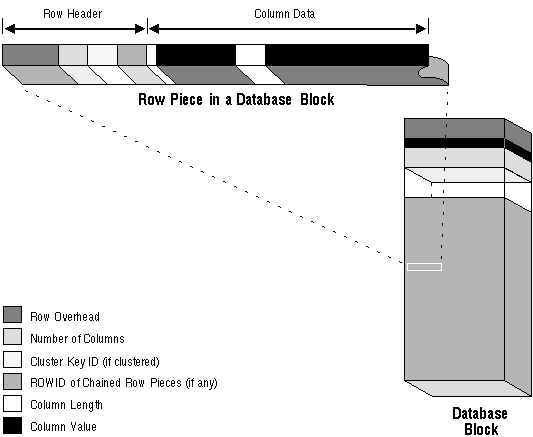
Figure 5 - 3. The Format of a Row Piece
The row header precedes the data and contains information about
- (for chained row pieces) chaining
- (for clustered data) cluster keys
A non-clustered row fully contained in one block has at least three bytes of row header. After the row header information, each row contains column length and data. The column length requires one byte for columns that store 250 bytes or less, or three bytes for columns that store more than 250 bytes, and precedes the column data. Space required for column data depends on the datatype. If the datatype of a column is variable length, the space required to hold a value can grow and shrink with updates to the data.
To conserve space, a null in a column only stores the column length (zero). Oracle does not store data for the null column. Also, for trailing null columns, Oracle does not store the column length because the row header signals the start of a new row (for example, the last three columns of a table are null, thus there is no information stored for those columns).
Note: Each row uses two bytes in the data block header's row directory.
Clustered rows contain the same information as non-clustered rows. In addition, they contain information that references the cluster key to which they belong. See "Clusters" .
Column Order
The column order is the same for all rows in a given table. Columns are usually stored in the order in which they were listed in the CREATE TABLE statement, but this is not guaranteed. For example, if you create a table with a column of datatype LONG, Oracle always stores this column last. Also, if a table is altered so that a new column is added, the new column becomes the last column stored.
In general, you should try to place columns that frequently contain nulls last so that rows take less space. Note, though, that if the table you are creating includes a LONG column as well, the benefits of placing frequently null columns last are lost.
ROWIDs of Row Pieces
The ROWID identifies each row piece by its location or address. Once assigned, a given row piece retains its ROWID until the corresponding row is deleted, or exported and imported using the IMPORT and EXPORT utilities. If the cluster key values of a row change, the row keeps the same ROWID, but also gets an additional pointer ROWID for the new values.
Because ROWIDs are constant for the lifetime of a row piece, it is useful to reference ROWIDs in SQL statements such as SELECT, UPDATE, and DELETE. See "ROWIDs and the ROWID Datatype" .
Nulls
A null is the absence of a value in a column of a row. Nulls indicate missing, unknown, or inapplicable data. A null should not be used to imply any other value, such as zero. A column allows nulls unless a NOT NULL or PRIMARY KEY integrity constraint has been defined for the column, in which case no row can be inserted without a value for that column.
Nulls are stored in the database if they fall between columns with data values. In these cases they require one byte to store the length of the column (zero). Trailing nulls in a row require no storage because a new row header signals that the remaining columns in the previous row are null. In tables with many columns, the columns more likely to contain nulls should be defined last to conserve disk space.
Most comparisons between nulls and other values are by definition neither true nor false, but unknown. To identify nulls in SQL, use the IS NULL predicate. Use the SQL function NVL to convert nulls to non-null values. For more information about comparisons using IS NULL and the NVL function, see Oracle7 Server SQL Reference.
Nulls are not indexed, except when the cluster key column value is null.
Default Values for Columns
You can assign a column of a table a default value so that when a new row is inserted and a value for the column is omitted, a default value is supplied automatically. Default column values work as though an INSERT statement actually specifies the default value.
Legal default values include any literal or expression that does not refer to a column, LEVEL, ROWNUM, or PRIOR. Default values can include the functions SYSDATE, USER, USERENV, and UID. The datatype of the default literal or expression must match or be convertible to the column datatype.
If a default value is not explicitly defined for a column, the default for the column is implicitly set to NULL.
When Default Values Are Inserted Relative to Integrity Constraint Checking
Integrity constraint checking occurs after the row with a default value is inserted. For example, in Figure 5 - 4, a row is inserted into the EMP table that does not include a value for the employee's department number. Because no value is supplied for the employee's department number, the DEPTNO column's default value "20" is supplied. After the default value is supplied, the FOREIGN KEY integrity constraint defined on the DEPTNO column is checked.
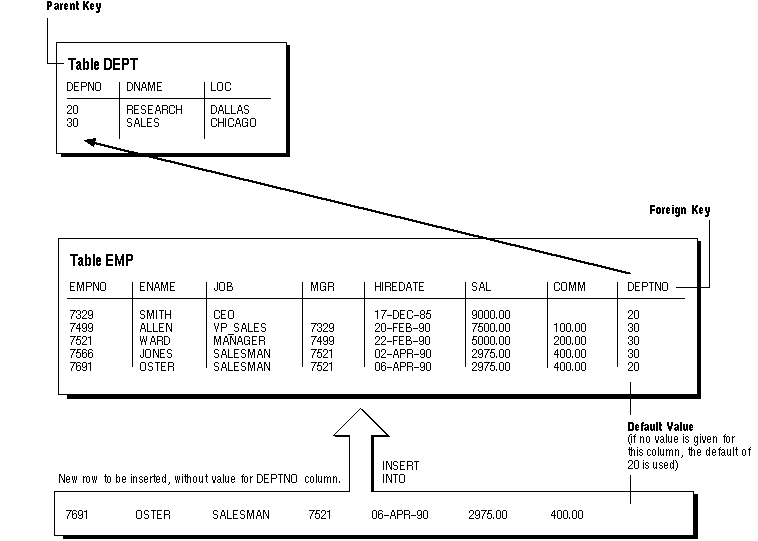
Figure 5 - 4. DEFAULT Column Values