





Note: Redo entries store low-level representations of database changes that cannot be mapped to user actions. Therefore, the contents of an online redo log file should never be edited or altered, and cannot be used for any application purposes such as auditing.
Redo entries are buffered in a "circular" fashion in the redo log buffer of the SGA and are written to one of the online redo log files by the Oracle background process Log Writer (LGWR). Whenever a transaction is committed, LGWR writes the transaction's redo entries from the redo log buffer of the SGA to an online redo log file, and a system change number (SCN) is assigned to identify the redo entries for each committed transaction.
However, redo entries can be written to an online redo log file before the corresponding transaction is committed. If the redo log buffer fills, or another transaction commits, LGWR flushes redo log entries in the redo log buffer to an online redo log file, of which some redo entries may not be committed. See "The Redo Log Buffer" ![[*]](jump.gif) for more information.
for more information.
LGWR writes to online redo log files in a circular fashion; when the current online redo log file is filled, LGWR begins writing to the next available online redo log file. When the last available online redo log file is filled, LGWR returns to the first online redo log file and writes to it, starting the cycle again. Figure 22 - 1 illustrates the circular writing of the online redo log file. The numbers next to each line indicate the sequence in which LGWR writes to each online redo log file.
Filled online redo log files are "available" to LGWR for reuse depending on whether archiving is enabled:
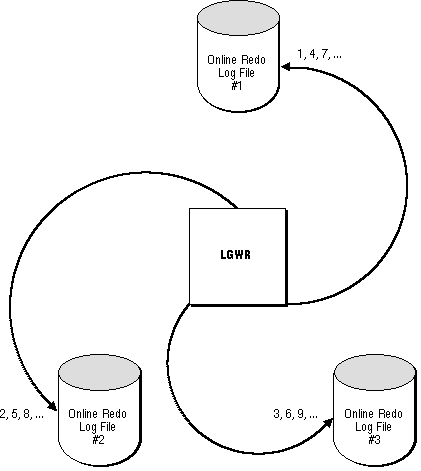
Figure 22 - 1. Circular Use of Online Redo Log Files by LGWR
Online redo log files that are required for instance recovery are called active online redo log files. Online redo log files that are not required for instance recovery are called inactive.
If archiving is enabled, an active online log file cannot be reused or overwritten until its contents are archived. If archiving is disabled, when the last online redo log file fills, writing continues by overwriting the first available active file. For more information about archiving options for the redo log, see "Database Archiving Modes" .
Oracle assigns each online redo log file a new log sequence number every time that a log switch occurs and LGWR begins writing to it. If online redo log files are archived, the archived redo log file retains its log sequence number. The online redo log file that is cycled back for use is given the next available log sequence number.
Each redo log file (including online and archived) is uniquely identified by its log sequence number. During instance or media recovery, Oracle properly applies redo log files in ascending order by using the log sequence number of necessary archived and online redo log files.
Checkpoints occur whether or not filled online redo log files are archived. If archiving is disabled, a checkpoint affecting an online redo log file must complete before the online redo log file can be reused by LGWR. If archiving is enabled, a checkpoint must complete and the filled online redo log file must be archived before it can be reused by LGWR.
Checkpoints can occur for all datafiles of the database (called database checkpoints) or can occur for only specific datafiles. The following list explains when checkpoints occur and what type happens in each situation:
The Mechanics of a Checkpoint When a checkpoint occurs, the checkpoint background process (CKPT) remembers the location of the next entry to be written in an online redo log file and signals the database writer background process (DBWR) to write the modified database buffers in the SGA to the datafiles on disk. CKPT then updates the headers of all control files and datafiles to reflect the latest checkpoint.
When a checkpoint is not happening, DBWR only writes the least-recently-used database buffers to disk to free buffers as needed for new data. However, as a checkpoint proceeds, DBWR writes data to the data files on behalf of both the checkpoint and ongoing database operations. DBWR writes a number of modified data buffers on behalf of the checkpoint, then writes the least recently used buffers, as needed, and then writes more dirty buffers for the checkpoint, and so on, until the checkpoint completes.
Depending on what signals a checkpoint to happen, the checkpoint can be either "normal" or "fast". With a normal checkpoint, DBWR writes a small number of data buffers each time it performs a write on behalf of a checkpoint. With a fast checkpoint, DBWR writes a large number of data buffers each time it performs a write on behalf of a checkpoint.
Therefore, by comparison, a normal checkpoint requires more I/Os to complete than a fast checkpoint. Because a fast checkpoint requires fewer I/Os, the checkpoint completes very quickly. However, a fast checkpoint can also detract from overall database performance if DBWR has a lot of other database work to complete. Events that trigger normal checkpoints include log switches and checkpoint intervals set by initialization parameters; events that trigger fast checkpoints include online tablespace backups, instance shutdowns, and database administrator-forced checkpoints.
Until a checkpoint completes, all online redo log files written since the last checkpoint are needed in case a database failure interrupts the checkpoint and instance recovery is necessary. Additionally, if LGWR cannot access an online redo log file for writing because a checkpoint has not completed, database operation suspends temporarily until the checkpoint completes and an online redo log file becomes available. In this case, the normal checkpoint becomes a fast checkpoint, so it completes as soon as possible.
For example, if only two online redo log files are used, and LGWR requires another log switch, the first online redo log file is unavailable to LGWR until the checkpoint for the previous log switch completes.
Note: The information that is recorded in the datafiles and control files as part of a checkpoint varies if the Oracle Parallel Server configuration is used; see Oracle7 Parallel Server Concepts & Administration.
You can set the initialization parameter LOG_CHECKPOINTS_TO_ALERT to determine if checkpoints are occurring at the desired frequency. The default value of NO for this parameter does not log checkpoints. When you set the parameter to YES, information about each checkpoint is recorded in the ALERT file.
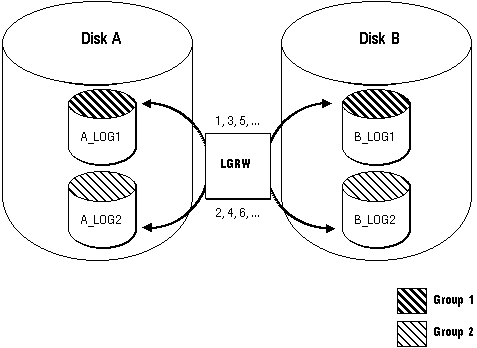
Figure 22 - 2. Multiplexed Online Redo Log Files
The corresponding online redo log files are called groups. Each online redo log file in a group is called a member. Notice that all members of a group are concurrently active (concurrently written to by LGWR), as indicated by the identical log sequence numbers assigned by LGWR. If a multiplexed online redo log is used, each member in a group must be the exact same size.
The Mechanics of a Multiplexed Online Redo Log LGWR always addresses all members of a group, whether the group contains one or many members. For example, LGWR always tries to write to all members of a given group concurrently, then to switch and concurrently write to all members of the next group, and so on. LGWR never writes concurrently to one member of a given group and one member of another group.
LGWR reacts differently when certain online redo log members are unavailable, depending on the reason for the file(s) being unavailable:
To always safeguard against a single point of online redo log failure, a multiplexed online redo log should be completely symmetrical: all groups of the online redo log should have the same number of members. However, Oracle does not require that a multiplexed online redo log be symmetrical. For example, one group can have only one member, while other groups can have two members. Oracle allows this behavior to provide for situations that temporarily affect some online redo log members but leave others unaffected (for example, a disk failure). The only requirement for an instance's online redo log, multiplexed or non-multiplexed, is that it be comprised of at least two groups. Figure 22 - 3 shows a legal and illegal multiplexed online redo log configuration.
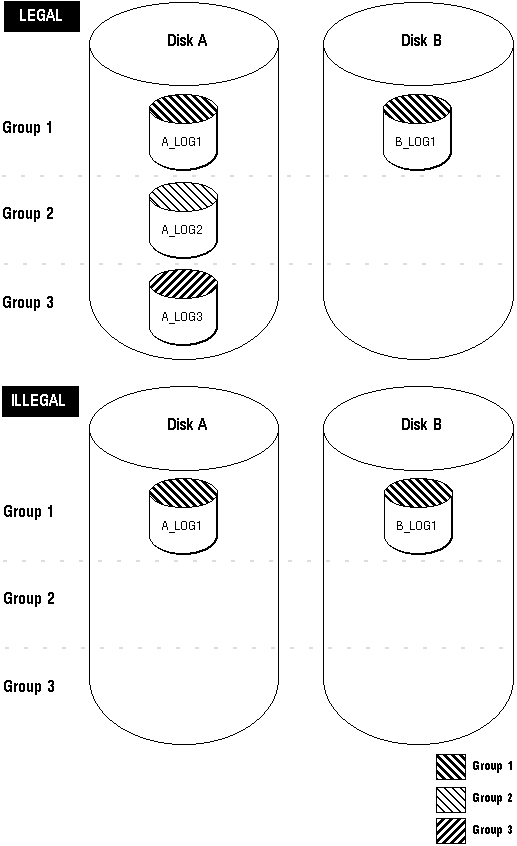
Figure 22 - 3. Legal and Illegal Multiplexed Online Redo Log Configuration
This manual describes how to configure and manage the online redo log when the Oracle Parallel Server is not used. The thread number can be assumed to be 1 in all discussions and examples of commands. For complete information about configuring the online redo log with the Oracle Parallel Server, see Oracle7 Parallel Server Concepts & Administration.