Oracle7 Server Concepts






What Is Optimization?
Optimization is the process of choosing the most efficient way to execute a SQL statement. This is an important step in the processing of any Data Manipulation Language statement (SELECT, INSERT, UPDATE, or DELETE). There may be many different ways for Oracle to execute such a statement, varying, for example, which tables or indexes are accessed in which order. The procedure used to execute a statement can greatly affect how quickly the statement executes. A part of Oracle called the optimizer chooses the way that it believes to be the most efficient.
The optimizer considers a number of factors to make what is usually the best choice among its alternatives. However, an application designer usually knows more about a particular application's data than the optimizer could know. Despite the best efforts of the optimizer, in some situations a developer can choose a more effective way to execute a SQL statement than the optimizer can.
Note: The optimizer may not make the same decisions from one version of Oracle to the next. In future versions of Oracle, the optimizer may make different decisions based on better, more sophisticated information available to it.
Execution Plans
To execute a Data Manipulation Language statement, Oracle may have to perform many steps. Each of these steps either physically retrieves rows of data from the database or prepares them in some way for the user issuing the statement. The combination of the steps Oracle uses to execute a statement is called an execution plan.
Example
This example shows an execution plan for this SQL statement:
SELECT ename, job, sal, dname
FROM emp, dept
WHERE emp.deptno = dept.deptno
AND NOT EXISTS
(SELECT *
FROM salgrade
WHERE emp.sal BETWEEN losal AND hisal);
This statement selects the name, job, salary, and department name for all employees whose salaries do not fall into any recommended salary range.
Figure 13 - 1 shows a graphical representation of the execution plan.
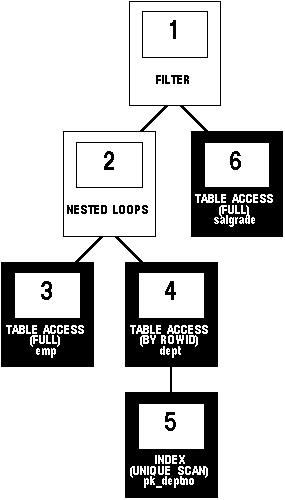
Figure 13 - 1. An Execution Plan
Steps of Execution Plan
Each step of the execution plan returns a set of rows that either are used by the next step or, in the last step, returned to the user or application issuing the SQL statement. A set of rows returned by a step is called a row source. Figure 13 - 1 is a hierarchical diagram showing the flow of rows from one step to another. The numbering of the steps reflects the order in which they are shown when you view the execution plan, as described in the section "The EXPLAIN PLAN Command", on 13-5. This generally is not the order in which the steps are executed.
Each step of the execution plan either retrieves rows from the database or accepts rows from one or more row sources as input:
- Steps 3 and 6 read all the rows of the EMP and SALGRADE tables, respectively.
- Step 5 looks up each DEPTNO value returned by step 3 in the PK_DEPTNO index. There it finds the ROWIDS of the associated rows in the DEPT table.
- Step 4 retrieves from the DEPT table the rows whose ROWIDs were returned by Step 5.
- Steps indicated by the clear boxes operate on row sources:
- Step 2 performs a nested loops operation, accepting row sources from Steps 3 and 4, joining each row from Step 3 source to its corresponding row in Step 4, and returning the resulting rows to Step 1.
- Step 1 performs a filter operation. It accepts row sources from Steps 2 and 6, eliminates rows from Step 2 that have a corresponding row in Step 6, and returns the remaining rows from step 2 to the user or application issuing the statement.
Access paths are discussed in the section "Choosing Access Paths" ![[*]](jump.gif) . Methods by which Oracle joins row sources are discussed in Oracle7 Server Tuning.
. Methods by which Oracle joins row sources are discussed in Oracle7 Server Tuning.
Order of Performing Execution Plan Steps
The steps of the execution plan are not performed in the order in which they are numbered. Oracle first performs the steps that appear as leaf nodes in the tree-structured graphical representation in Figure 13 - 1. The rows returned by each step become the row sources of its parent step. Then Oracle performs the parent steps.
To execute the statement for Figure 13 - 1, for example, Oracle performs the steps in this order:
- First, Oracle performs Step 3, and returns the resulting rows, one by one, to Step 2.
- For each row returned by Step 3, Oracle performs these steps:
- Oracle performs Step 5 and returns the resulting ROWID to Step 4.
- Oracle performs Step 4 and returns the resulting row to Step 2.
- Oracle performs Step 2, accepting a single row from Step 3 and a single row from Step 4, and returning a single row to Step 1.
- Oracle performs Step 6 and returns the resulting row, if any, to Step 1.
- Oracle performs Step 1. If a row is returned from Step 6, Oracle returns the row from Step 2 to the user issuing the SQL statement.
Note that Oracle performs Steps 5, 4, 2, 6, and 1 once for each row returned by Step 3. Many parent steps require only a single row from their child steps before they can be executed. For such a parent step, Oracle performs the parent step (and possibly the rest of the execution plan) as soon as a single row has been returned from the child step. If the parent of that parent step also can be activated by the return of a single row, then it is executed as well. Thus the execution can cascade up the tree possibly to encompass the rest of the execution plan. Oracle performs the parent step and all cascaded steps once for each row in turn retrieved by the child step. The parent steps that are triggered for each row returned by a child step include table accesses, index accesses, nested loops joins, and filters.
Some parent steps require all rows from their child steps before they can be performed. For such a parent step, Oracle cannot perform the parent step until all rows have been returned from the child step. Such parent steps include sorts, sort-merge joins, group functions, and aggregates.
The EXPLAIN PLAN Command
You can examine the execution plan chosen by the optimizer for a SQL statement by using the EXPLAIN PLAN command. This command causes the optimizer to choose the execution plan and then inserts data describing the plan into a database table. The following is such a description for the statement examined in the previous section:
ID OPERATION OPTIONS OBJECT_NAME
------------------------------------------------------------
0 SELECT STATEMENT
1 FILTER
2 NESTED LOOPS
3 TABLE ACCESS FULL EMP
4 TABLE ACCESS BY ROWID DEPT
5 INDEX UNIQUE SCAN PK_DEPTNO
6 TABLE ACCESS FULL SALGRADE
You can obtain such a listing by using the EXPLAIN PLAN command and then querying the output table. For information on how to use this command and produce and interpret its output, see Appendix A "Performance Diagnostic Tools" of Oracle7 Server Tuning.
Each box in Figure 13 - 1 and each row in the output table corresponds to a single step in the execution plan. For each row in the listing, the value in the ID column is the value shown in the corresponding box in Figure 13 - 1.
Oracle's Approaches to Optimization
To choose an execution plan for a SQL statement, the optimizer uses one of these approaches:
| rule-based | Using the rule-based approach, the optimizer chooses an execution plan based on the access paths available and the ranks of these access paths in Table 13 - 1. |
| cost-based | Using the cost-based approach, the optimizer considers available access paths and factors in information based on statistics in the data dictionary for the objects (tables, clusters, or indexes) accessed by the statement to determine which execution plan is most efficient. The cost-based approach also considers hints, or optimization suggestions in the statement placed in a comment. |
The Rule-Based Approach
The rule-based approach chooses execution plans based on heuristically ranked operations. If there is more than one way to execute a SQL statement, the rule-based approach always uses the operation with the lower rank. Usually, operations of lower rank execute faster than those associated with constructs of higher rank.
The Cost-Based Approach
Conceptually, the cost-based approach consists of these steps:
1. The optimizer generates a set of potential execution plans for the statement based on its available access paths and hints.
2. The optimizer estimates the cost of each execution plan based on the data distribution and storage characteristics statistics for the tables, clusters, and indexes in the data dictionary.
The cost is an estimated value proportional to the expected elapsed time needed to execute the statement using the execution plan. The optimizer calculates the cost based on the estimated computer resources including but not limited to I/O, CPU time, and memory required to execute the statement using the plan. Execution plans with greater costs take more time to execute than those with smaller costs.
3. The optimizer compares the costs of the execution plans and chooses the one with the smallest cost.
Goal of the Cost-Based Approach By default, the goal of the cost-based approach is the best throughput, or minimal elapsed time necessary to process all rows accessed by the statement.
Oracle can also optimize a statement with the goal of best response time, or minimal elapsed time necessary to process the first row accessed by a SQL statement. For information on how the optimizer chooses an optimization approach and goal, see Oracle7 Server Tuning.
Statistics Used for the Cost-Based Approach The cost-based approach uses statistics to estimate the cost of each execution plan. These statistics quantify the data distribution and storage characteristics of tables, columns, and indexes. These statistics are generated using the ANALYZE command. Using these statistics, the optimizer estimates how much I/O, CPU time, and memory are required to execute a SQL statement using a particular execution plan.
The statistics are visible through these data dictionary views:
- USER_TABLES, ALL_TABLES, and DBA_TABLES
- USER_TAB_COLUMNS, ALL_TAB_COLUMNS, and DBA_TAB_COLUMNS
- USER_INDEXES, ALL_INDEXES, and DBA_INDEXES
- USER_CLUSTERS and DBA_CLUSTERS
For information on these statistics, see the Oracle7 Server Reference.
Histograms
Oracle's cost based optimizer (CBO) uses data value histograms to get accurate estimates of the distribution of column data. Histograms provide improved selectivity estimates in the presence of data skew, resulting in optimal execution plans with non-uniform data distributions. You generate histograms by using the ANALYZE command.
One of the fundamental capabilities of any cost-based optimizer is determining the selectivity of predicates that appear in queries. In releases earlier than 7.3, Oracle's cost-based optimizer supported accurate selectivity estimates, assuming that the attribute domains (a table's columns) were uniformly distributed. However, most attribute domains are not uniformly distributed.
Histograms enable the cost-based optimizer to describe the distributions of non-uniform domains by using height balanced histograms on specified attributes. Selectivity estimates are used to decide when to use an index and to choose the order that tables are joined.
Example
Consider a column C with values between 1 and 100 and a histogram with 10 buckets. If the data in C is uniformly distributed, this histogram would look like this, where the numbers are the endpoint values.
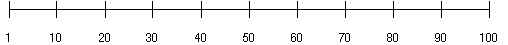
The number of rows in each bucket is one tenth the total number of rows in the table.
If the data is not uniformly distributed, the histogram might look like this:
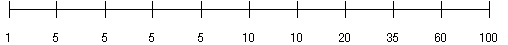
In this case, most of the rows have the value 5 for the column. In the uniform example, 4/10 of the rows had values between 60 and 100, in the non-uniform example, only 1/10 of the rows have values between 60 and 100.
When to Use Histograms
For many users, it is appropriate to use the FOR ALL INDEXED COLUMNS option for creating histograms because indexed columns are typically the columns most often used in WHERE clauses.
You can view histograms by using the following views:
Histograms are useful only when they reflect the current data distribution of a given column. If the data distribution is not static, the histogram should be updated frequently. The data need not be static as long as the distribution remains constant.
Histograms can affect performance and should be used only when they substantially improve query plans. Histograms are not useful for columns with the following characteristics:
- All predicates on the column use bind variables.
- The column data is uniformly distributed.
- The column is not used in WHERE clauses of queries.
- The column is unique and is used only with equality predicates.
For More Information
See Oracle7 Server Tuning.