





The calculations in the procedure rely on average column lengths of the columns that constitute an index; therefore, if column lengths in each row of a table are relatively constant with respect to the indexed columns, the estimates calculated by the following procedure are more accurate.
To Estimate Space for Indexes
Note: Several calculations are required to obtain a final estimate, and several of the constants (indicated by *) provided are operating system-specific. Your estimates should not significantly differ from actual values.
See Also: See your operating system-specific Oracle documentation for any substantial deviations from the constants provided in the following procedure.
block header size = fixed header + variable transaction header
where:
| fixed header* 113 bytes |
| variable transaction header* 24*I I is the value of INITRANS for the index. |
block header = 113 + (24*2) bytes
= 161 bytes
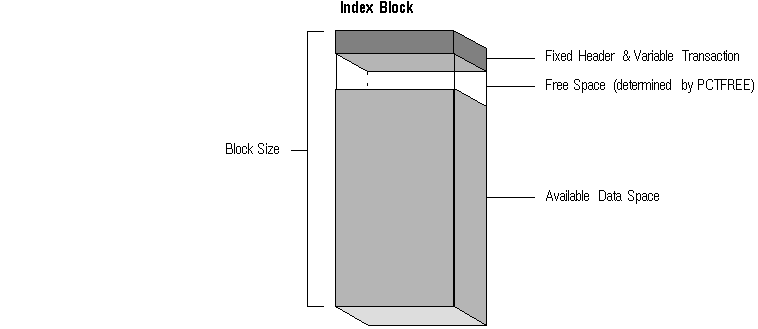 Figure A - 2. Calculating the Space for an Index
Figure A - 2. Calculating the Space for an Index
available
data = (block size - block header) -
space per block ((block size - block header)*(PCTFREE/100))
The block size of a database is set during database creation and can be determined using the Server Manager command SHOW, if necessary:
SHOW PARAMETERS db_block_size;
If the data block size is 2K and PCTFREE=10 for a given index, the total space for new data in data blocks allocated for the index is:
available data space per block
= (2048 bytes - 161 bytes) -
((2048 bytes - 161 bytes)*(10/100))
= (1887 bytes) - (1887 bytes * 0.1)
= 1887 bytes - 188.7 bytes
= 1698.3 bytes
bytes/entry = entry header + ROWID length + F + V + D
where:
| entry header 2 bytes |
| ROWID length 6 bytes |
| F Total length bytes of all columns that store 127 bytes or less. The number of length bytes required by each column of this type is 1 byte. |
| V Total length bytes of all columns that store more than 127 bytes. The number of length bytes required by each column of this type is 2 bytes. |
| D Combined data space of all index columns (from Step 3). |
 Figure A - 3. Calculating the Average Size of an Index Entry
Figure A - 3. Calculating the Average Size of an Index EntryFor example, given that D is calculated to be 22 bytes and that the index is comprised of three VARCHAR(10) columns, the total average entry size of the index is:
avg. entry size = 2 + 6 + (1 * 3) + (2 * 0) + 22 bytes
= 33 bytes
Note: For a non-unique index, the ROWID is considered another column, so it must have one length byte.
# blocks for index =
# not null rows
1.05 * _________________________________________________
FLOOR(avail. data space per block/avg. entry size)
Note: The additional 5% added to this result (by means of the multiplication factor of 1.05) accounts for the extra space required for branch blocks of the index.
For example, continuing with the previous example, and assuming you estimate that indexed table will have 10000 rows that contain non-null values in the columns that constitute the index:
# blocks for index =
10000 * 33 bytes
1.05 * _____________________________________
FLOOR(1700 bytes/33 bytes)*(33 bytes)
This results in 204 blocks. The number of bytes can be calculated by multiplying the number of blocks by the data block size.
Remember that this procedure provides a reasonable estimate of an index's size, not an exact number of blocks or bytes. Once you have estimated the size of a index, you can use this information when specifying the INITIAL storage parameter (size of the index's initial extent) in your corresponding CREATE INDEX statement.
Note: Temporary space is not required if the NOSORT option is included in the CREATE INDEX command. However, you cannot specify this option when creating a cluster index.